 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDriving in Real Life with Inverse Reinforcement Learning
Jun 07, 2022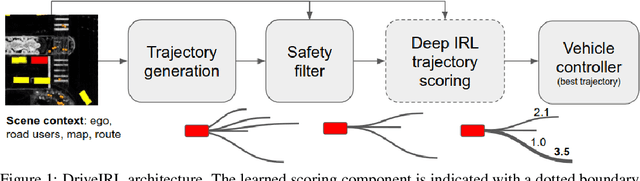


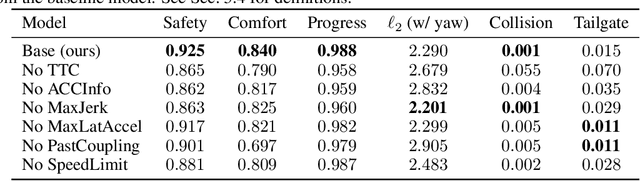
In this paper, we introduce the first learning-based planner to drive a car in dense, urban traffic using Inverse Reinforcement Learning (IRL). Our planner, DriveIRL, generates a diverse set of trajectory proposals, filters these trajectories with a lightweight and interpretable safety filter, and then uses a learned model to score each remaining trajectory. The best trajectory is then tracked by the low-level controller of our self-driving vehicle. We train our trajectory scoring model on a 500+ hour real-world dataset of expert driving demonstrations in Las Vegas within the maximum entropy IRL framework. DriveIRL's benefits include: a simple design due to only learning the trajectory scoring function, relatively interpretable features, and strong real-world performance. We validated DriveIRL on the Las Vegas Strip and demonstrated fully autonomous driving in heavy traffic, including scenarios involving cut-ins, abrupt braking by the lead vehicle, and hotel pickup/dropoff zones. Our dataset will be made public to help further research in this area.
Efficient Ridesharing Dispatch Using Multi-Agent Reinforcement Learning
Jun 18, 2020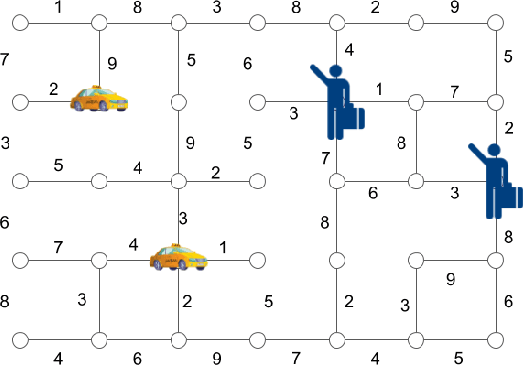
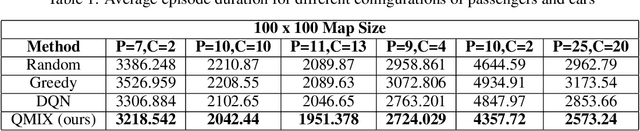
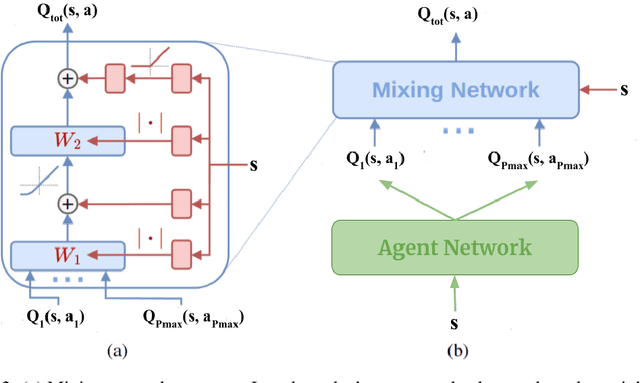
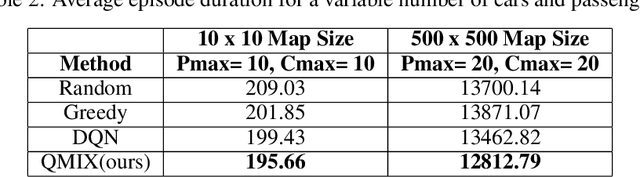
With the advent of ride-sharing services, there is a huge increase in the number of people who rely on them for various needs. Most of the earlier approaches tackling this issue required handcrafted functions for estimating travel times and passenger waiting times. Traditional Reinforcement Learning (RL) based methods attempting to solve the ridesharing problem are unable to accurately model the complex environment in which taxis operate. Prior Multi-Agent Deep RL based methods based on Independent DQN (IDQN) learn decentralized value functions prone to instability due to the concurrent learning and exploring of multiple agents. Our proposed method based on QMIX is able to achieve centralized training with decentralized execution. We show that our model performs better than the IDQN baseline on a fixed grid size and is able to generalize well to smaller or larger grid sizes. Also, our algorithm is able to outperform IDQN baseline in the scenario where we have a variable number of passengers and cars in each episode. Code for our paper is publicly available at: https://github.com/UMich-ML-Group/RL-Ridesharing.