 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyle Equalization: Unsupervised Learning of Controllable Generative Sequence Models
Paper and Code
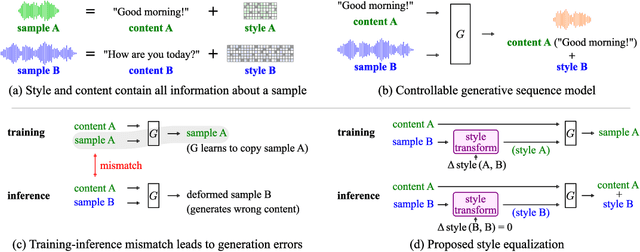
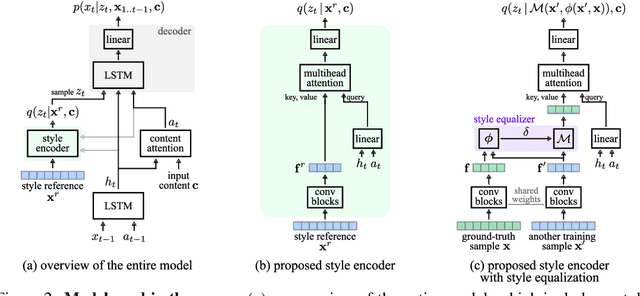
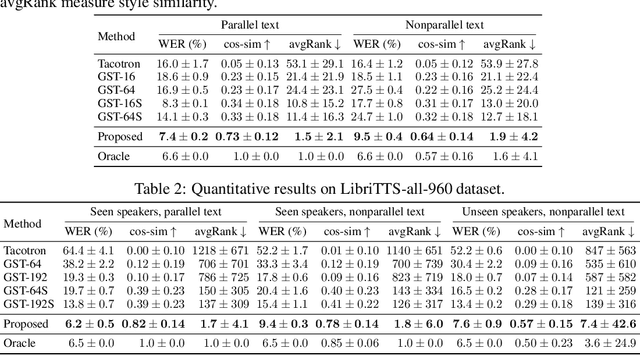

Controllable generative sequence models with the capability to extract and replicate the style of specific examples enable many applications, including narrating audiobooks in different voices, auto-completing and auto-correcting written handwriting, and generating missing training samples for downstream recognition tasks. However, typical training algorithms for these controllable sequence generative models suffer from the training-inference mismatch, where the same sample is used as content and style input during training but different samples are given during inference. In this paper, we tackle the training-inference mismatch encountered during unsupervised learning of controllable generative sequence models. By introducing a style transformation module that we call style equalization, we enable training using different content and style samples and thereby mitigate the training-inference mismatch. To demonstrate its generality, we applied style equalization to text-to-speech and text-to-handwriting synthesis on three datasets. Our models achieve state-of-the-art style replication with a similar mean style opinion score as the real data. Moreover, the proposed method enables style interpolation between sequences and generates novel styles.