 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode-switched inspired losses for generic spoken dialog representations
Paper and Code

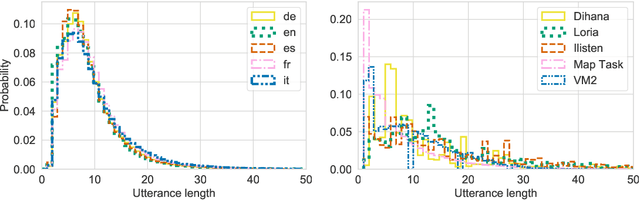
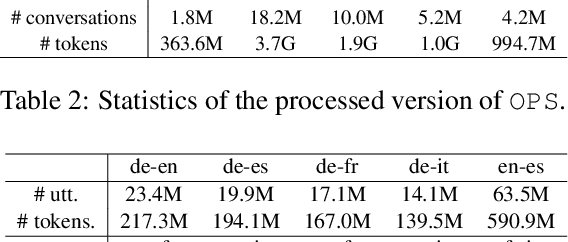
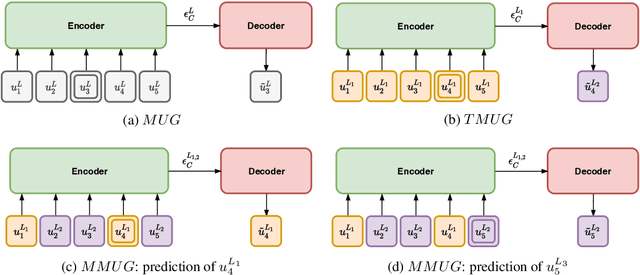
Spoken dialog systems need to be able to handle both multiple languages and multilinguality inside a conversation (\textit{e.g} in case of code-switching). In this work, we introduce new pretraining losses tailored to learn multilingual spoken dialog representations. The goal of these losses is to expose the model to code-switched language. To scale up training, we automatically build a pretraining corpus composed of multilingual conversations in five different languages (French, Italian, English, German and Spanish) from \texttt{OpenSubtitles}, a huge multilingual corpus composed of 24.3G tokens. We test the generic representations on \texttt{MIAM}, a new benchmark composed of five dialog act corpora on the same aforementioned languages as well as on two novel multilingual downstream tasks (\textit{i.e} multilingual mask utterance retrieval and multilingual inconsistency identification). Our experiments show that our new code switched-inspired losses achieve a better performance in both monolingual and multilingual settings.