 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Impact of Word Splitting on the Semantic Content of Contextualized Word Representations
Feb 22, 2024When deriving contextualized word representations from language models, a decision needs to be made on how to obtain one for out-of-vocabulary (OOV) words that are segmented into subwords. What is the best way to represent these words with a single vector, and are these representations of worse quality than those of in-vocabulary words? We carry out an intrinsic evaluation of embeddings from different models on semantic similarity tasks involving OOV words. Our analysis reveals, among other interesting findings, that the quality of representations of words that are split is often, but not always, worse than that of the embeddings of known words. Their similarity values, however, must be interpreted with caution.
ALL Dolphins Are Intelligent and SOME Are Friendly: Probing BERT for Nouns' Semantic Properties and their Prototypicality
Oct 12, 2021
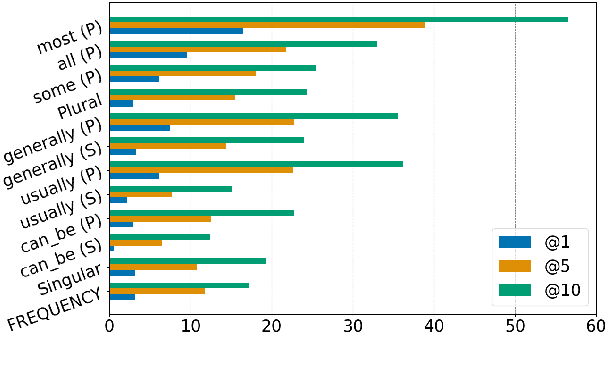

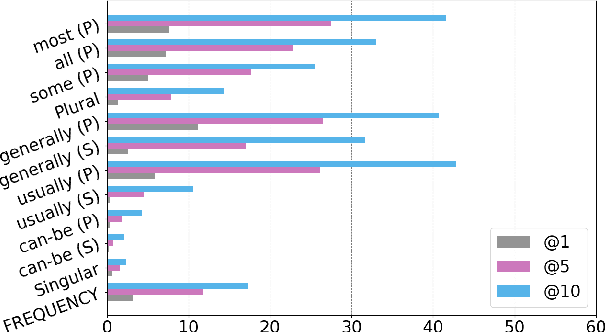
Large scale language models encode rich commonsense knowledge acquired through exposure to massive data during pre-training, but their understanding of entities and their semantic properties is unclear. We probe BERT (Devlin et al., 2019) for the properties of English nouns as expressed by adjectives that do not restrict the reference scope of the noun they modify (as in "red car"), but instead emphasise some inherent aspect ("red strawberry"). We base our study on psycholinguistics datasets that capture the association strength between nouns and their semantic features. We probe BERT using cloze tasks and in a classification setting, and show that the model has marginal knowledge of these features and their prevalence as expressed in these datasets. We discuss factors that make evaluation challenging and impede drawing general conclusions about the models' knowledge of noun properties. Finally, we show that when tested in a fine-tuning setting addressing entailment, BERT successfully leverages the information needed for reasoning about the meaning of adjective-noun constructions outperforming previous methods.
Scalar Adjective Identification and Multilingual Ranking
May 03, 2021
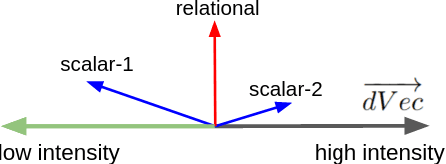
The intensity relationship that holds between scalar adjectives (e.g., nice < great < wonderful) is highly relevant for natural language inference and common-sense reasoning. Previous research on scalar adjective ranking has focused on English, mainly due to the availability of datasets for evaluation. We introduce a new multilingual dataset in order to promote research on scalar adjectives in new languages. We perform a series of experiments and set performance baselines on this dataset, using monolingual and multilingual contextual language models. Additionally, we introduce a new binary classification task for English scalar adjective identification which examines the models' ability to distinguish scalar from relational adjectives. We probe contextualised representations and report baseline results for future comparison on this task.
Let's Play Mono-Poly: BERT Can Reveal Words' Polysemy Level and Partitionability into Senses
Apr 29, 2021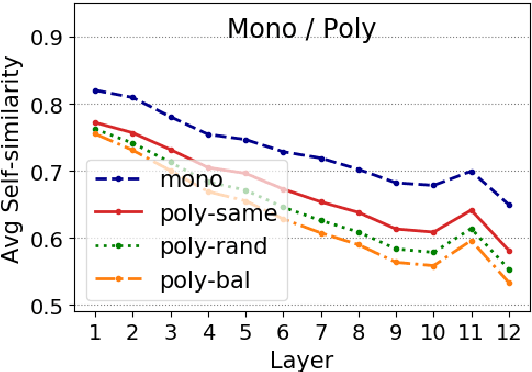

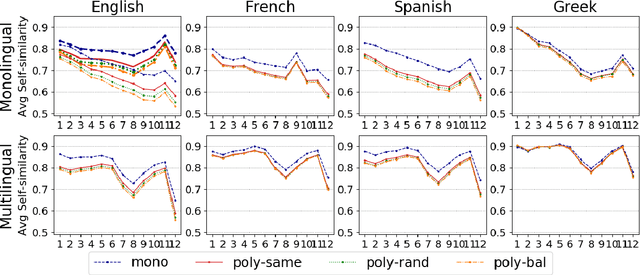
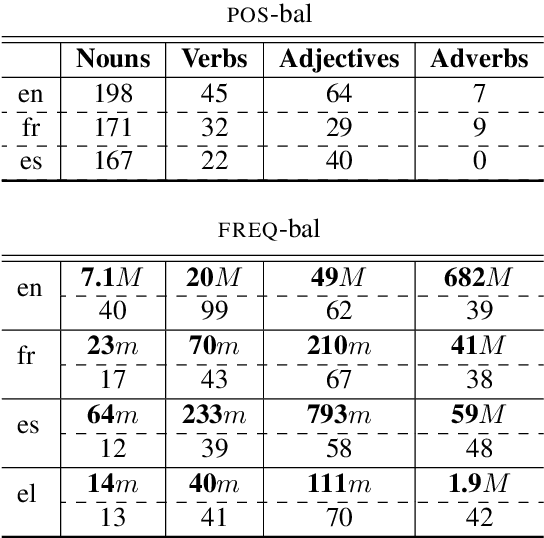
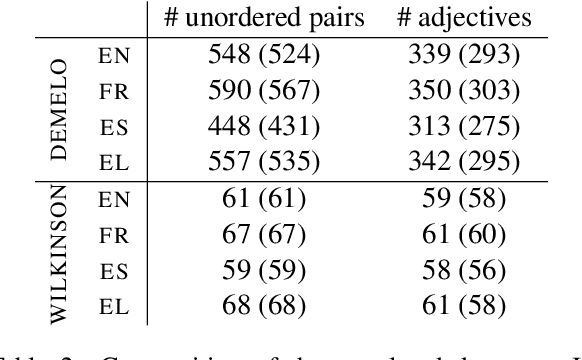
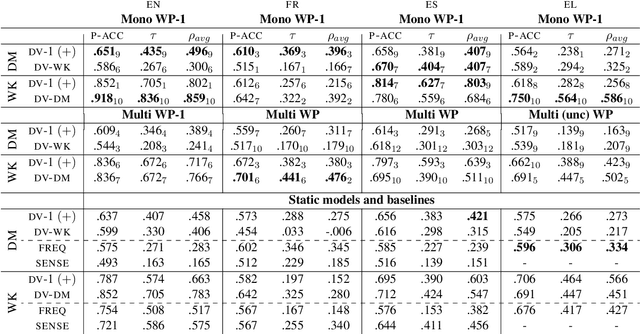
Pre-trained language models (LMs) encode rich information about linguistic structure but their knowledge about lexical polysemy remains unclear. We propose a novel experimental setup for analysing this knowledge in LMs specifically trained for different languages (English, French, Spanish and Greek) and in multilingual BERT. We perform our analysis on datasets carefully designed to reflect different sense distributions, and control for parameters that are highly correlated with polysemy such as frequency and grammatical category. We demonstrate that BERT-derived representations reflect words' polysemy level and their partitionability into senses. Polysemy-related information is more clearly present in English BERT embeddings, but models in other languages also manage to establish relevant distinctions between words at different polysemy levels. Our results contribute to a better understanding of the knowledge encoded in contextualised representations and open up new avenues for multilingual lexical semantics research.
BERT Knows Punta Cana is not just beautiful, it's gorgeous: Ranking Scalar Adjectives with Contextualised Representations
Oct 06, 2020

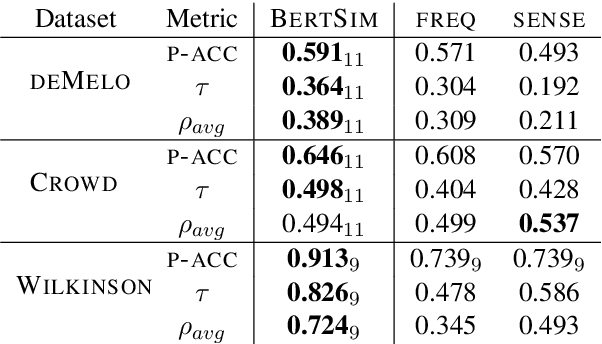

Adjectives like pretty, beautiful and gorgeous describe positive properties of the nouns they modify but with different intensity. These differences are important for natural language understanding and reasoning. We propose a novel BERT-based approach to intensity detection for scalar adjectives. We model intensity by vectors directly derived from contextualised representations and show they can successfully rank scalar adjectives. We evaluate our models both intrinsically, on gold standard datasets, and on an Indirect Question Answering task. Our results demonstrate that BERT encodes rich knowledge about the semantics of scalar adjectives, and is able to provide better quality intensity rankings than static embeddings and previous models with access to dedicated resources.
MULTISEM at SemEval-2020 Task 3: Fine-tuning BERT for Lexical Meaning
Jul 24, 2020
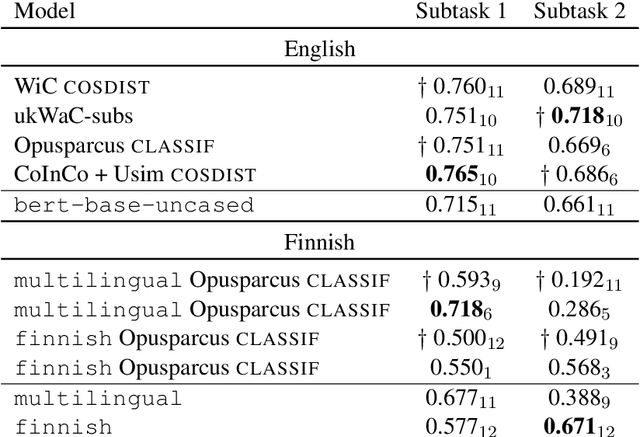
We present the MULTISEM systems submitted to SemEval 2020 Task 3: Graded Word Similarity in Context (GWSC). We experiment with injecting semantic knowledge into pre-trained BERT models through fine-tuning on lexical semantic tasks related to GWSC. We use existing semantically annotated datasets and propose to approximate similarity through automatically generated lexical substitutes in context. We participate in both GWSC subtasks and address two languages, English and Finnish. Our best English models occupy the third and fourth positions in the ranking for the two subtasks. Performance is lower for the Finnish models which are mid-ranked in the respective subtasks, highlighting the important role of data availability for fine-tuning.
Exploring sentence informativeness
Jul 22, 2019
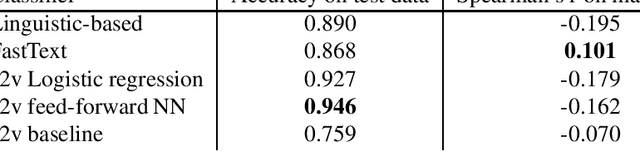


This study is a preliminary exploration of the concept of informativeness -how much information a sentence gives about a word it contains- and its potential benefits to building quality word representations from scarce data. We propose several sentence-level classifiers to predict informativeness, and we perform a manual annotation on a set of sentences. We conclude that these two measures correspond to different notions of informativeness. However, our experiments show that using the classifiers' predictions to train word embeddings has an impact on embedding quality.
Word Usage Similarity Estimation with Sentence Representations and Automatic Substitutes
May 20, 2019
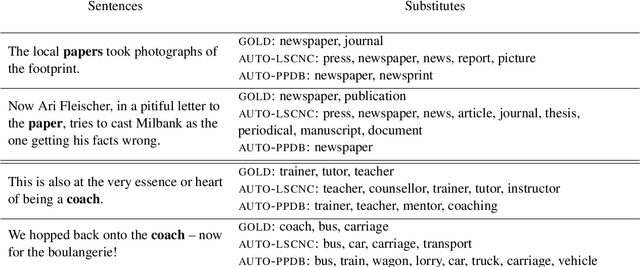
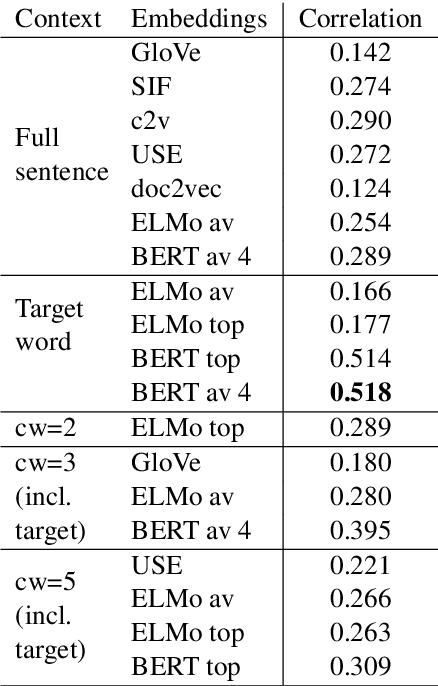
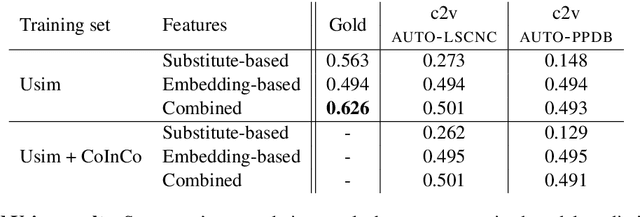
Usage similarity estimation addresses the semantic proximity of word instances in different contexts. We apply contextualized (ELMo and BERT) word and sentence embeddings to this task, and propose supervised models that leverage these representations for prediction. Our models are further assisted by lexical substitute annotations automatically assigned to word instances by context2vec, a neural model that relies on a bidirectional LSTM. We perform an extensive comparison of existing word and sentence representations on benchmark datasets addressing both graded and binary similarity. The best performing models outperform previous methods in both settings.