 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet's Play Mono-Poly: BERT Can Reveal Words' Polysemy Level and Partitionability into Senses
Paper and Code
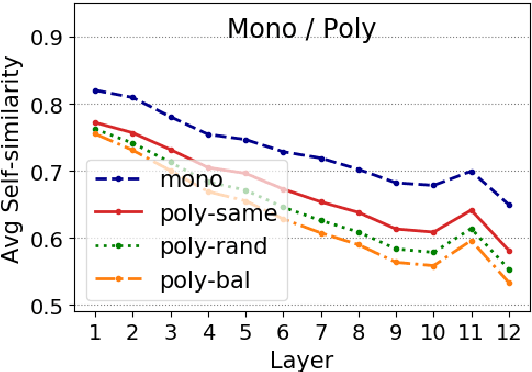

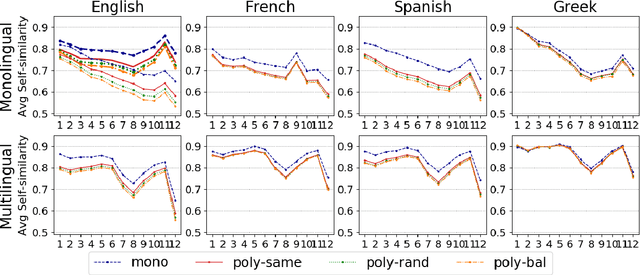
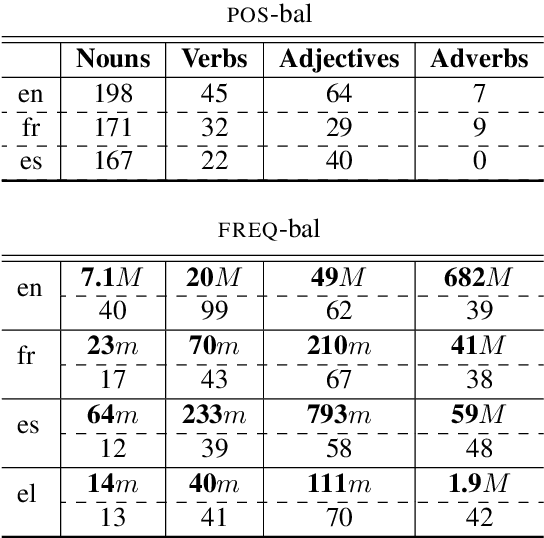
Pre-trained language models (LMs) encode rich information about linguistic structure but their knowledge about lexical polysemy remains unclear. We propose a novel experimental setup for analysing this knowledge in LMs specifically trained for different languages (English, French, Spanish and Greek) and in multilingual BERT. We perform our analysis on datasets carefully designed to reflect different sense distributions, and control for parameters that are highly correlated with polysemy such as frequency and grammatical category. We demonstrate that BERT-derived representations reflect words' polysemy level and their partitionability into senses. Polysemy-related information is more clearly present in English BERT embeddings, but models in other languages also manage to establish relevant distinctions between words at different polysemy levels. Our results contribute to a better understanding of the knowledge encoded in contextualised representations and open up new avenues for multilingual lexical semantics research.