Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord Usage Similarity Estimation with Sentence Representations and Automatic Substitutes
Paper and Code

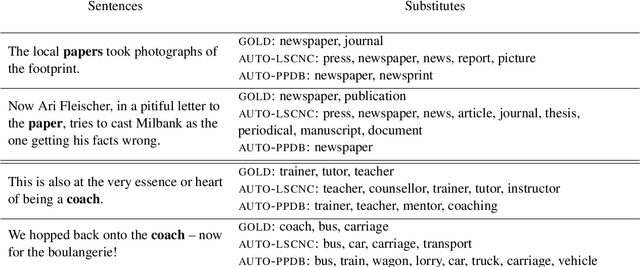
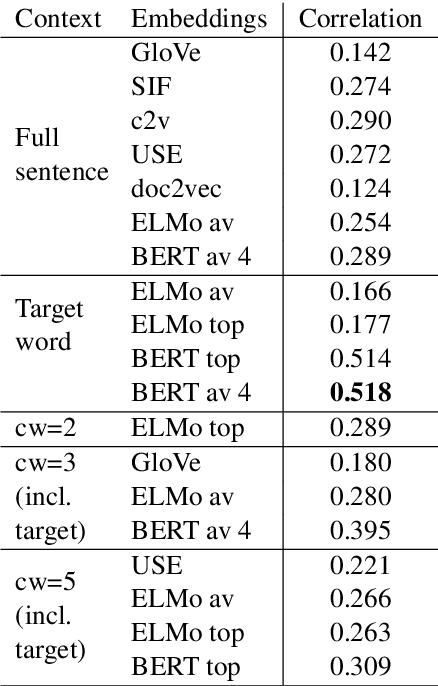
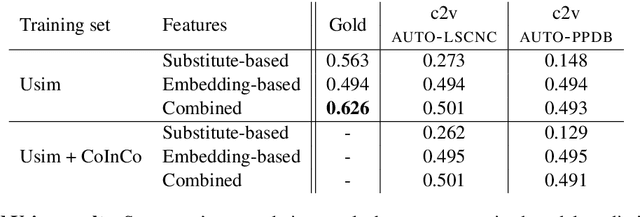
Usage similarity estimation addresses the semantic proximity of word instances in different contexts. We apply contextualized (ELMo and BERT) word and sentence embeddings to this task, and propose supervised models that leverage these representations for prediction. Our models are further assisted by lexical substitute annotations automatically assigned to word instances by context2vec, a neural model that relies on a bidirectional LSTM. We perform an extensive comparison of existing word and sentence representations on benchmark datasets addressing both graded and binary similarity. The best performing models outperform previous methods in both settings.
* *SEM 2019
View paper on