Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring sentence informativeness
Paper and Code
Jul 22, 2019
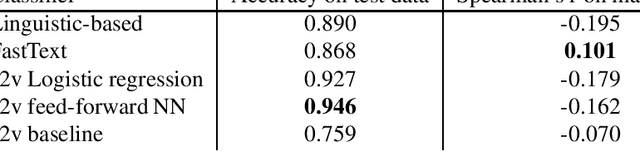


This study is a preliminary exploration of the concept of informativeness -how much information a sentence gives about a word it contains- and its potential benefits to building quality word representations from scarce data. We propose several sentence-level classifiers to predict informativeness, and we perform a manual annotation on a set of sentences. We conclude that these two measures correspond to different notions of informativeness. However, our experiments show that using the classifiers' predictions to train word embeddings has an impact on embedding quality.
* Published at TALN 2019
View paper on