 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalar Adjective Identification and Multilingual Ranking
Paper and Code

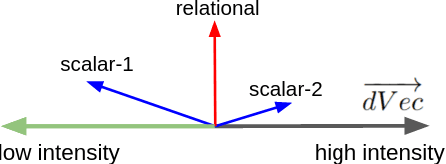
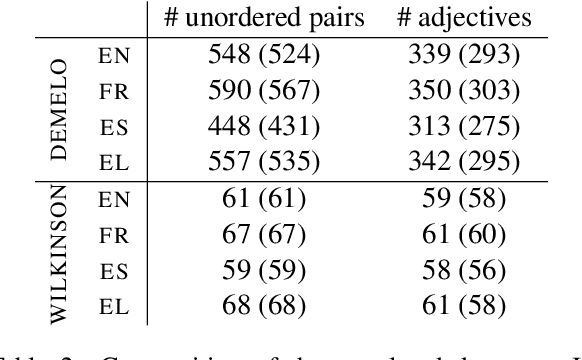
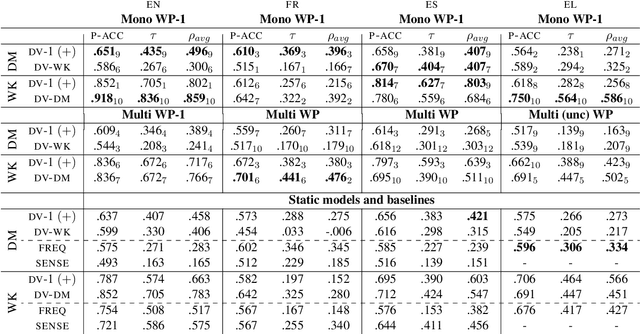
The intensity relationship that holds between scalar adjectives (e.g., nice < great < wonderful) is highly relevant for natural language inference and common-sense reasoning. Previous research on scalar adjective ranking has focused on English, mainly due to the availability of datasets for evaluation. We introduce a new multilingual dataset in order to promote research on scalar adjectives in new languages. We perform a series of experiments and set performance baselines on this dataset, using monolingual and multilingual contextual language models. Additionally, we introduce a new binary classification task for English scalar adjective identification which examines the models' ability to distinguish scalar from relational adjectives. We probe contextualised representations and report baseline results for future comparison on this task.