 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALL Dolphins Are Intelligent and SOME Are Friendly: Probing BERT for Nouns' Semantic Properties and their Prototypicality
Paper and Code

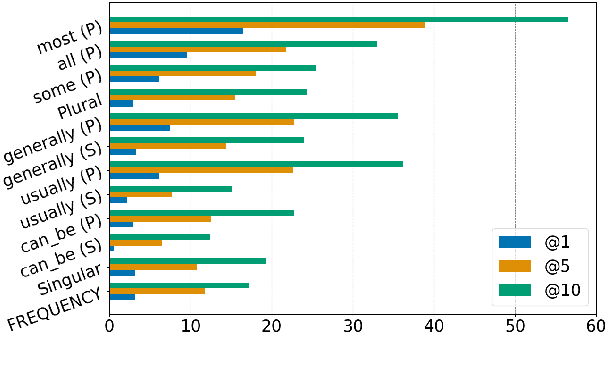

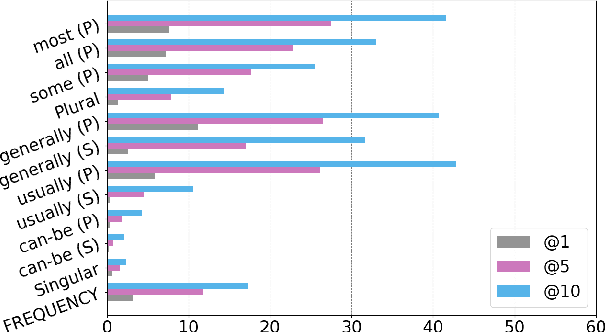
Large scale language models encode rich commonsense knowledge acquired through exposure to massive data during pre-training, but their understanding of entities and their semantic properties is unclear. We probe BERT (Devlin et al., 2019) for the properties of English nouns as expressed by adjectives that do not restrict the reference scope of the noun they modify (as in "red car"), but instead emphasise some inherent aspect ("red strawberry"). We base our study on psycholinguistics datasets that capture the association strength between nouns and their semantic features. We probe BERT using cloze tasks and in a classification setting, and show that the model has marginal knowledge of these features and their prevalence as expressed in these datasets. We discuss factors that make evaluation challenging and impede drawing general conclusions about the models' knowledge of noun properties. Finally, we show that when tested in a fine-tuning setting addressing entailment, BERT successfully leverages the information needed for reasoning about the meaning of adjective-noun constructions outperforming previous methods.