 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Differentiable Surrogate Losses for Structured Prediction
Paper and Code
Nov 18, 2024
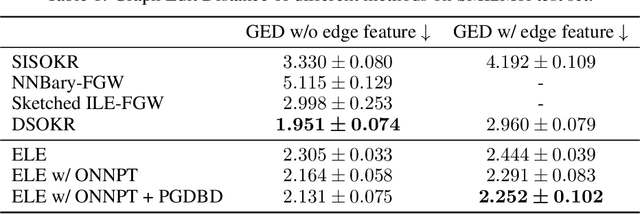


Structured prediction involves learning to predict complex structures rather than simple scalar values. The main challenge arises from the non-Euclidean nature of the output space, which generally requires relaxing the problem formulation. Surrogate methods build on kernel-induced losses or more generally, loss functions admitting an Implicit Loss Embedding, and convert the original problem into a regression task followed by a decoding step. However, designing effective losses for objects with complex structures presents significant challenges and often requires domain-specific expertise. In this work, we introduce a novel framework in which a structured loss function, parameterized by neural networks, is learned directly from output training data through Contrastive Learning, prior to addressing the supervised surrogate regression problem. As a result, the differentiable loss not only enables the learning of neural networks due to the finite dimension of the surrogate space but also allows for the prediction of new structures of the output data via a decoding strategy based on gradient descent. Numerical experiments on supervised graph prediction problems show that our approach achieves similar or even better performance than methods based on a pre-defined kernel.