 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAFALDA: A Benchmark and Comprehensive Study of Fallacy Detection and Classification
Nov 16, 2023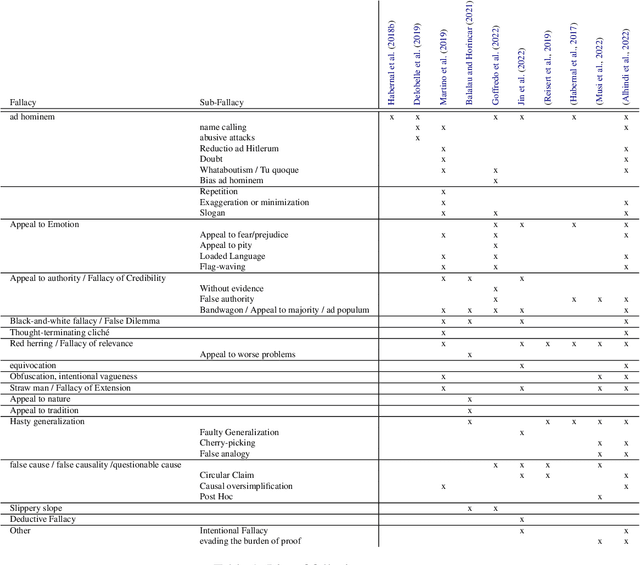

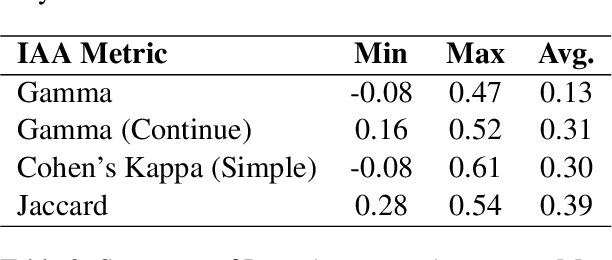
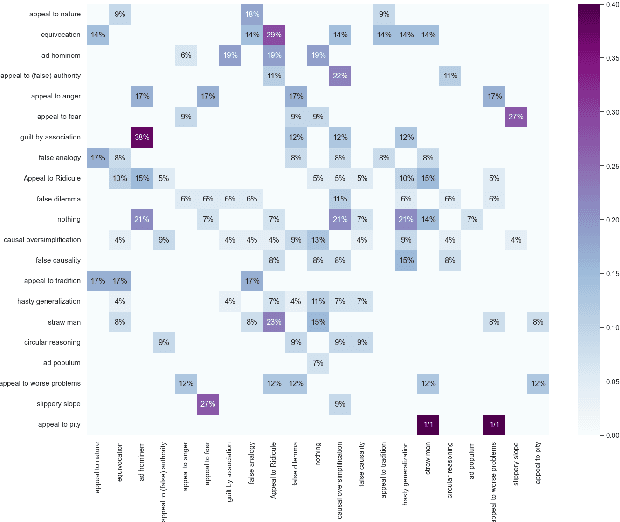
Fallacies can be used to spread disinformation, fake news, and propaganda, underlining the importance of their detection. Automated detection and classification of fallacies, however, remain challenging, mainly because of the innate subjectivity of the task and the need for a comprehensive, unified approach in existing research. Addressing these limitations, our study introduces a novel taxonomy of fallacies that aligns and refines previous classifications, a new annotation scheme tailored for subjective NLP tasks, and a new evaluation method designed to handle subjectivity, adapted to precision, recall, and F1-Score metrics. Using our annotation scheme, the paper introduces MAFALDA (Multi-level Annotated FALlacy DAtaset), a gold standard dataset. MAFALDA is based on examples from various previously existing fallacy datasets under our unified taxonomy across three levels of granularity. We then evaluate several language models under a zero-shot learning setting using MAFALDA to assess their fallacy detection and classification capability. Our comprehensive evaluation not only benchmarks the performance of these models but also provides valuable insights into their strengths and limitations in addressing fallacious reasoning.