 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMCOMET: A Large-Scale Multimodal Commonsense Knowledge Graph for Contextual Reasoning
Mar 01, 2026We present MMCOMET, the first multimodal commonsense knowledge graph (MMKG) that integrates physical, social, and eventive knowledge. MMCOMET extends the ATOMIC2020 knowledge graph to include a visual dimension, through an efficient image retrieval process, resulting in over 900K multimodal triples. This new resource addresses a major limitation of existing MMKGs in supporting complex reasoning tasks like image captioning and storytelling. Through a standard visual storytelling experiment, we show that our holistic approach enables the generation of richer, coherent, and contextually grounded stories than those produced using text-only knowledge. This resource establishes a new foundation for multimodal commonsense reasoning and narrative generation.
Tailored Emotional LLM-Supporter: Enhancing Cultural Sensitivity
Aug 11, 2025Large language models (LLMs) show promise in offering emotional support and generating empathetic responses for individuals in distress, but their ability to deliver culturally sensitive support remains underexplored due to lack of resources. In this work, we introduce CultureCare, the first dataset designed for this task, spanning four cultures and including 1729 distress messages, 1523 cultural signals, and 1041 support strategies with fine-grained emotional and cultural annotations. Leveraging CultureCare, we (i) develop and test four adaptation strategies for guiding three state-of-the-art LLMs toward culturally sensitive responses; (ii) conduct comprehensive evaluations using LLM judges, in-culture human annotators, and clinical psychologists; (iii) show that adapted LLMs outperform anonymous online peer responses, and that simple cultural role-play is insufficient for cultural sensitivity; and (iv) explore the application of LLMs in clinical training, where experts highlight their potential in fostering cultural competence in future therapists.
In-depth Research Impact Summarization through Fine-Grained Temporal Citation Analysis
May 20, 2025Understanding the impact of scientific publications is crucial for identifying breakthroughs and guiding future research. Traditional metrics based on citation counts often miss the nuanced ways a paper contributes to its field. In this work, we propose a new task: generating nuanced, expressive, and time-aware impact summaries that capture both praise (confirmation citations) and critique (correction citations) through the evolution of fine-grained citation intents. We introduce an evaluation framework tailored to this task, showing moderate to strong human correlation on subjective metrics such as insightfulness. Expert feedback from professors reveals a strong interest in these summaries and suggests future improvements.
Can large language models generate salient negative statements?
May 26, 2023We examine the ability of large language models (LLMs) to generate salient (interesting) negative statements about real-world entities; an emerging research topic of the last few years. We probe the LLMs using zero- and k-shot unconstrained probes, and compare with traditional methods for negation generation, i.e., pattern-based textual extractions and knowledge-graph-based inferences, as well as crowdsourced gold statements. We measure the correctness and salience of the generated lists about subjects from different domains. Our evaluation shows that guided probes do in fact improve the quality of generated negatives, compared to the zero-shot variant. Nevertheless, using both prompts, LLMs still struggle with the notion of factuality of negatives, frequently generating many ambiguous statements, or statements with negative keywords but a positive meaning.
Completeness, Recall, and Negation in Open-World Knowledge Bases: A Survey
May 09, 2023General-purpose knowledge bases (KBs) are a cornerstone of knowledge-centric AI. Many of them are constructed pragmatically from Web sources, and are thus far from complete. This poses challenges for the consumption as well as the curation of their content. While several surveys target the problem of completing incomplete KBs, the first problem is arguably to know whether and where the KB is incomplete in the first place, and to which degree. In this survey we discuss how knowledge about completeness, recall, and negation in KBs can be expressed, extracted, and inferred. We cover (i) the logical foundations of knowledge representation and querying under partial closed-world semantics; (ii) the estimation of this information via statistical patterns; (iii) the extraction of information about recall from KBs and text; (iv) the identification of interesting negative statements; and (v) relaxed notions of relative recall. This survey is targeted at two types of audiences: (1) practitioners who are interested in tracking KB quality, focusing extraction efforts, and building quality-aware downstream applications; and (2) data management, knowledge base and semantic web researchers who wish to understand the state of the art of knowledge bases beyond the open-world assumption. Consequently, our survey presents both fundamental methodologies and their working, and gives practice-oriented recommendations on how to choose between different approaches for a problem at hand.
* 33 pages, 5 tables
UnCommonSense: Informative Negative Knowledge about Everyday Concepts
Aug 22, 2022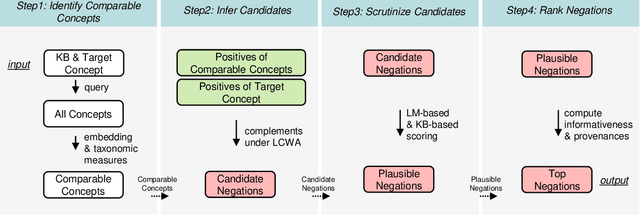
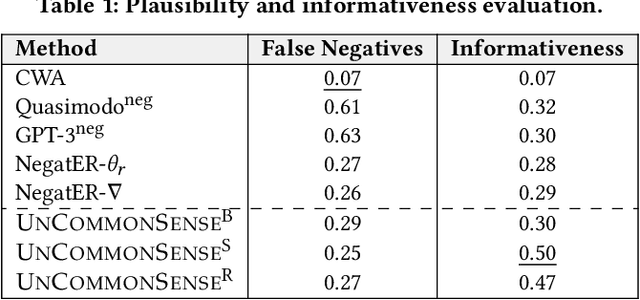
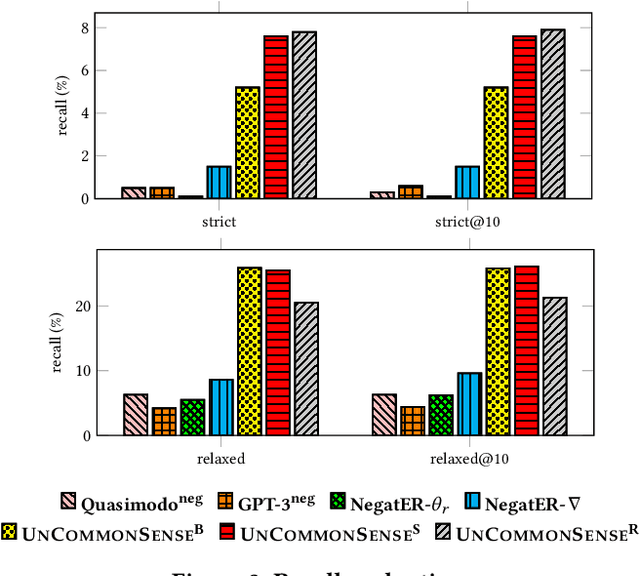
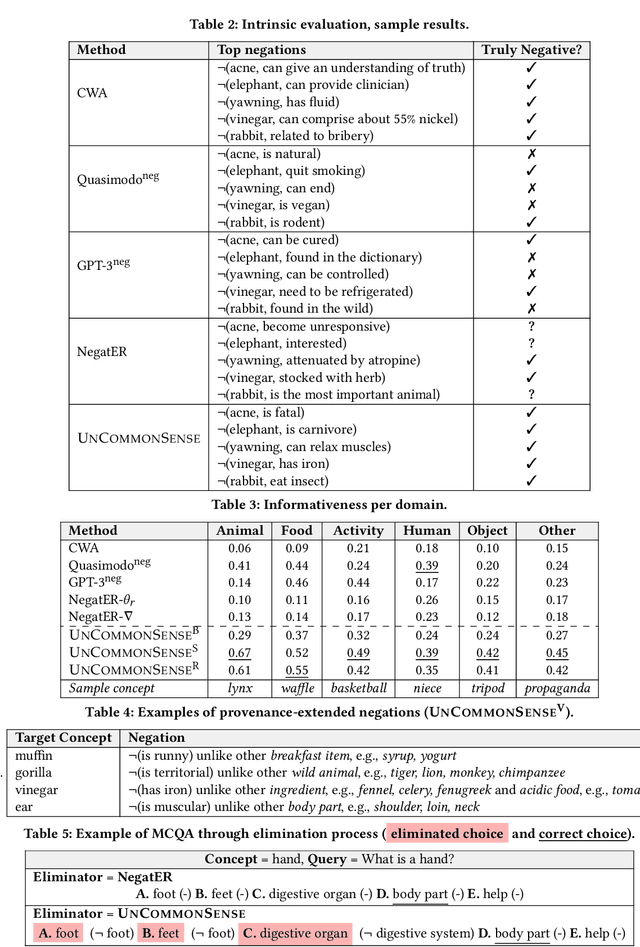
Commonsense knowledge about everyday concepts is an important asset for AI applications, such as question answering and chatbots. Recently, we have seen an increasing interest in the construction of structured commonsense knowledge bases (CSKBs). An important part of human commonsense is about properties that do not apply to concepts, yet existing CSKBs only store positive statements. Moreover, since CSKBs operate under the open-world assumption, absent statements are considered to have unknown truth rather than being invalid. This paper presents the UNCOMMONSENSE framework for materializing informative negative commonsense statements. Given a target concept, comparable concepts are identified in the CSKB, for which a local closed-world assumption is postulated. This way, positive statements about comparable concepts that are absent for the target concept become seeds for negative statement candidates. The large set of candidates is then scrutinized, pruned and ranked by informativeness. Intrinsic and extrinsic evaluations show that our method significantly outperforms the state-of-the-art. A large dataset of informative negations is released as a resource for future research.
Negative Statements Considered Useful
Jan 20, 2020
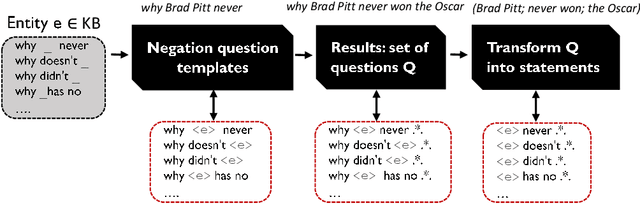


Knowledge bases (KBs), pragmatic collections of knowledge about notable entities, are an important asset in applications such as search, question answering and dialogue. Rooted in a long tradition in knowledge representation, all popular KBs only store positive information, while they abstain from taking any stance towards statements not contained in them. In this paper, we make the case for explicitly stating interesting statements which are not true. Negative statements would be important to overcome current limitations of question answering, yet due to their potential abundance, any effort towards compiling them needs a tight coupling with ranking. We introduce two approaches towards compiling negative statements. (i) In peer-based statistical inferences, we compare entities with highly related entities in order to derive potential negative statements, which we then rank using supervised and unsupervised features. (ii) In query-log-based text extraction, we use a pattern-based approach for harvesting search engine query logs. Experimental results show that both approaches hold promising and complementary potential. Along with this paper, we publish the first datasets on interesting negative information, containing over 1.1M statements for 100K popular Wikidata entities.