 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNegative Statements Considered Useful
Paper and Code

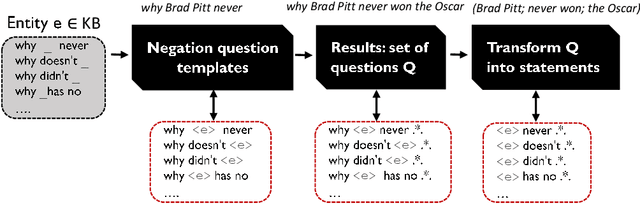


Knowledge bases (KBs), pragmatic collections of knowledge about notable entities, are an important asset in applications such as search, question answering and dialogue. Rooted in a long tradition in knowledge representation, all popular KBs only store positive information, while they abstain from taking any stance towards statements not contained in them. In this paper, we make the case for explicitly stating interesting statements which are not true. Negative statements would be important to overcome current limitations of question answering, yet due to their potential abundance, any effort towards compiling them needs a tight coupling with ranking. We introduce two approaches towards compiling negative statements. (i) In peer-based statistical inferences, we compare entities with highly related entities in order to derive potential negative statements, which we then rank using supervised and unsupervised features. (ii) In query-log-based text extraction, we use a pattern-based approach for harvesting search engine query logs. Experimental results show that both approaches hold promising and complementary potential. Along with this paper, we publish the first datasets on interesting negative information, containing over 1.1M statements for 100K popular Wikidata entities.