 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKGrEaT: A Framework to Evaluate Knowledge Graphs via Downstream Tasks
Aug 21, 2023

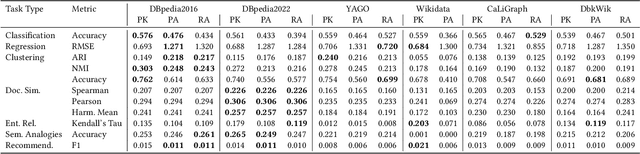
In recent years, countless research papers have addressed the topics of knowledge graph creation, extension, or completion in order to create knowledge graphs that are larger, more correct, or more diverse. This research is typically motivated by the argumentation that using such enhanced knowledge graphs to solve downstream tasks will improve performance. Nonetheless, this is hardly ever evaluated. Instead, the predominant evaluation metrics - aiming at correctness and completeness - are undoubtedly valuable but fail to capture the complete picture, i.e., how useful the created or enhanced knowledge graph actually is. Further, the accessibility of such a knowledge graph is rarely considered (e.g., whether it contains expressive labels, descriptions, and sufficient context information to link textual mentions to the entities of the knowledge graph). To better judge how well knowledge graphs perform on actual tasks, we present KGrEaT - a framework to estimate the quality of knowledge graphs via actual downstream tasks like classification, clustering, or recommendation. Instead of comparing different methods of processing knowledge graphs with respect to a single task, the purpose of KGrEaT is to compare various knowledge graphs as such by evaluating them on a fixed task setup. The framework takes a knowledge graph as input, automatically maps it to the datasets to be evaluated on, and computes performance metrics for the defined tasks. It is built in a modular way to be easily extendable with additional tasks and datasets.
NASTyLinker: NIL-Aware Scalable Transformer-based Entity Linker
Mar 13, 2023Entity Linking (EL) is the task of detecting mentions of entities in text and disambiguating them to a reference knowledge base. Most prevalent EL approaches assume that the reference knowledge base is complete. In practice, however, it is necessary to deal with the case of linking to an entity that is not contained in the knowledge base (NIL entity). Recent works have shown that, instead of focusing only on affinities between mentions and entities, considering inter-mention affinities can be used to represent NIL entities by producing clusters of mentions. At the same time, inter-mention affinities can help to substantially improve linking performance for known entities. With NASTyLinker, we introduce an EL approach that is aware of NIL entities and produces corresponding mention clusters while maintaining high linking performance for known entities. The approach clusters mentions and entities based on dense representations from Transformers and resolves conflicts (if more than one entity is assigned to a cluster) by computing transitive mention-entity affinities. We show the effectiveness and scalability of NASTyLinker on NILK, a dataset that is explicitly constructed to evaluate EL with respect to NIL entities. Further, we apply the presented approach to an actual EL task, namely to knowledge graph population by linking entities in Wikipedia listings, and provide an analysis of the outcome.
Transformer-based Subject Entity Detection in Wikipedia Listings
Oct 04, 2022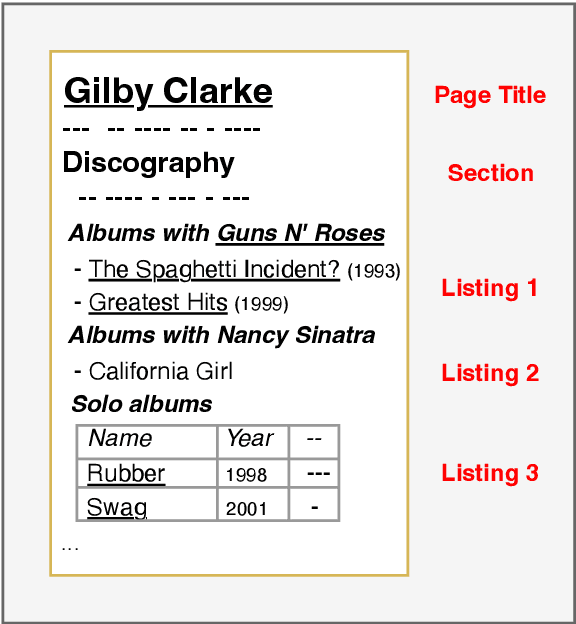
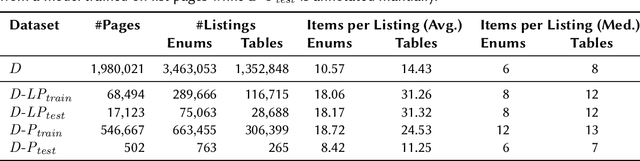
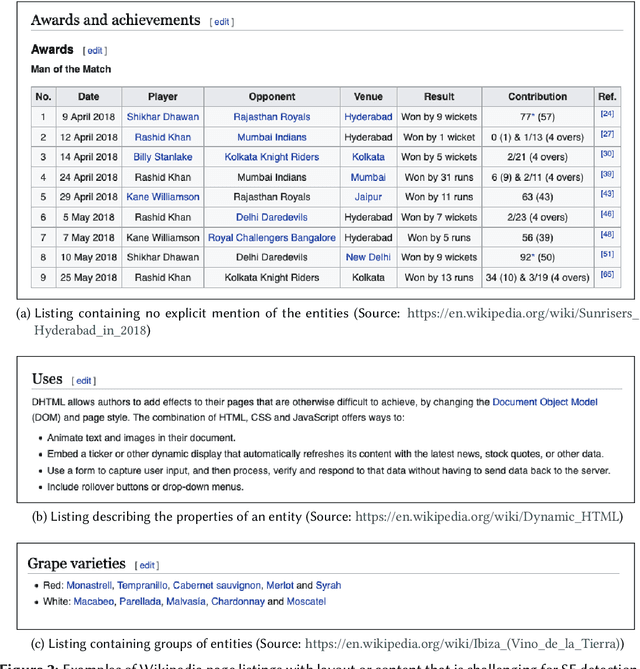
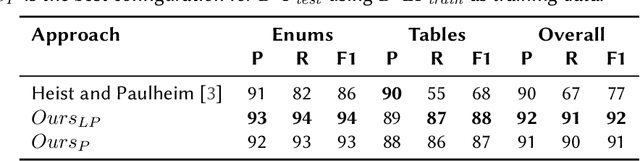
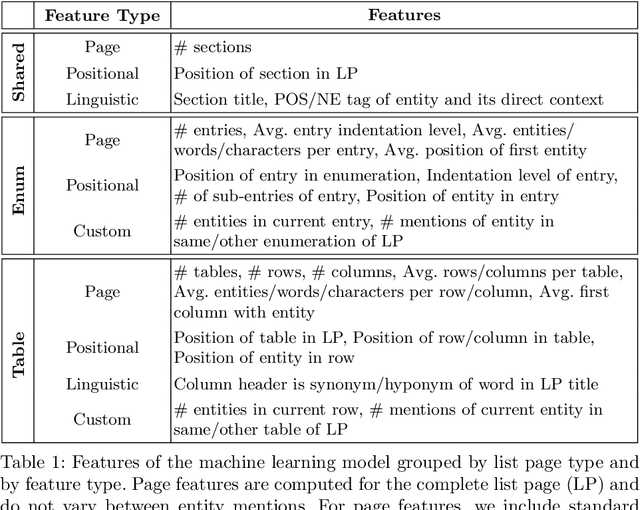
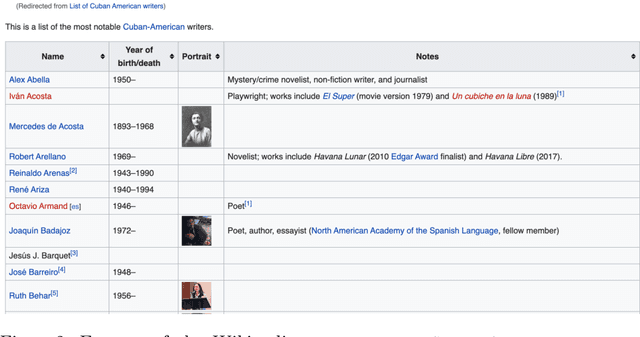
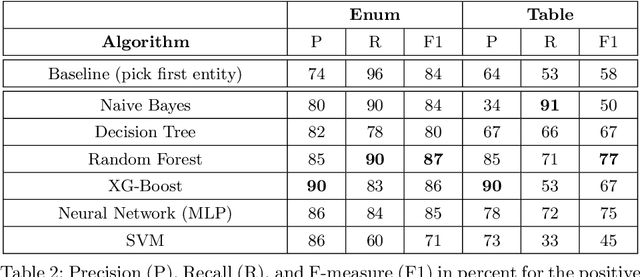
In tasks like question answering or text summarisation, it is essential to have background knowledge about the relevant entities. The information about entities - in particular, about long-tail or emerging entities - in publicly available knowledge graphs like DBpedia or CaLiGraph is far from complete. In this paper, we present an approach that exploits the semi-structured nature of listings (like enumerations and tables) to identify the main entities of the listing items (i.e., of entries and rows). These entities, which we call subject entities, can be used to increase the coverage of knowledge graphs. Our approach uses a transformer network to identify subject entities at the token-level and surpasses an existing approach in terms of performance while being bound by fewer limitations. Due to a flexible input format, it is applicable to any kind of listing and is, unlike prior work, not dependent on entity boundaries as input. We demonstrate our approach by applying it to the complete Wikipedia corpus and extracting 40 million mentions of subject entities with an estimated precision of 71% and recall of 77%. The results are incorporated in the most recent version of CaLiGraph.
The CaLiGraph Ontology as a Challenge for OWL Reasoners
Oct 11, 2021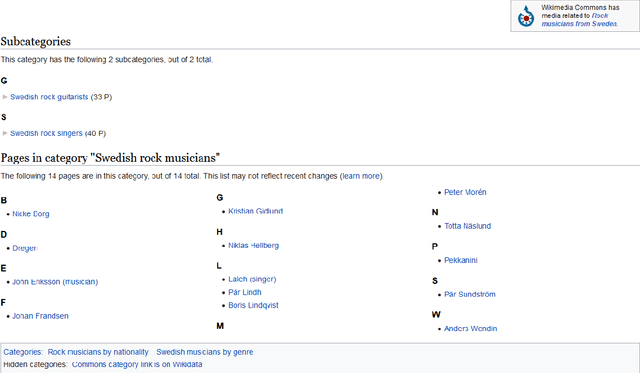


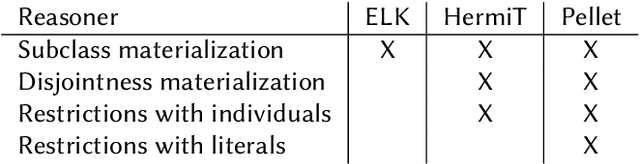
CaLiGraph is a large-scale cross-domain knowledge graph generated from Wikipedia by exploiting the category system, list pages, and other list structures in Wikipedia, containing more than 15 million typed entities and around 10 million relation assertions. Other than knowledge graphs such as DBpedia and YAGO, whose ontologies are comparably simplistic, CaLiGraph also has a rich ontology, comprising more than 200,000 class restrictions. Those two properties - a large A-box and a rich ontology - make it an interesting challenge for benchmarking reasoners. In this paper, we show that a reasoning task which is particularly relevant for CaLiGraph, i.e., the materialization of owl:hasValue constraints into assertions between individuals and between individuals and literals, is insufficiently supported by available reasoning systems. We provide differently sized benchmark subsets of CaLiGraph, which can be used for performance analysis of reasoning systems.
Information Extraction From Co-Occurring Similar Entities
Feb 15, 2021
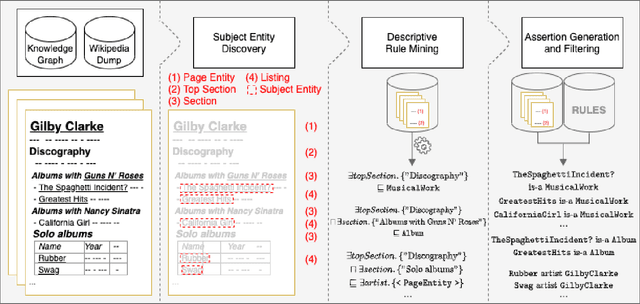
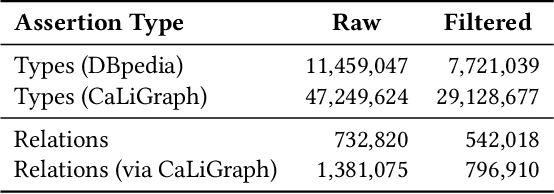
Knowledge about entities and their interrelations is a crucial factor of success for tasks like question answering or text summarization. Publicly available knowledge graphs like Wikidata or DBpedia are, however, far from being complete. In this paper, we explore how information extracted from similar entities that co-occur in structures like tables or lists can help to increase the coverage of such knowledge graphs. In contrast to existing approaches, we do not focus on relationships within a listing (e.g., between two entities in a table row) but on the relationship between a listing's subject entities and the context of the listing. To that end, we propose a descriptive rule mining approach that uses distant supervision to derive rules for these relationships based on a listing's context. Extracted from a suitable data corpus, the rules can be used to extend a knowledge graph with novel entities and assertions. In our experiments we demonstrate that the approach is able to extract up to 3M novel entities and 30M additional assertions from listings in Wikipedia. We find that the extracted information is of high quality and thus suitable to extend Wikipedia-based knowledge graphs like DBpedia, YAGO, and CaLiGraph. For the case of DBpedia, this would result in an increase of covered entities by roughly 50%.
A Knowledge Graph for Assessing Agressive Tax Planning Strategies
Aug 17, 2020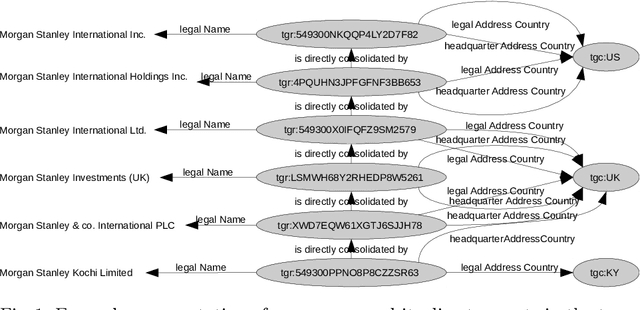
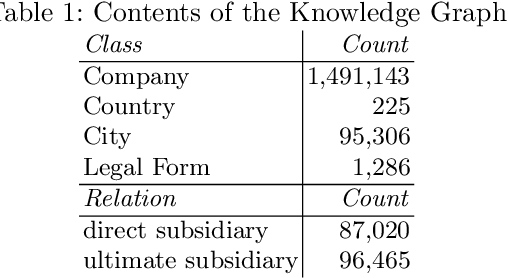


The taxation of multi-national companies is a complex field, since it is influenced by the legislation of several states. Laws in different states may have unforeseen interaction effects, which can be exploited by allowing multinational companies to minimize taxes, a concept known as tax planning. In this paper, we present a knowledge graph of multinational companies and their relationships, comprising almost 1.5M business entities. We show that commonly known tax planning strategies can be formulated as subgraph queries to that graph, which allows for identifying companies using certain strategies. Moreover, we demonstrate that we can identify anomalies in the graph which hint at potential tax planning strategies, and we show how to enhance those analyses by incorporating information from Wikidata using federated queries.
Knowledge Graphs on the Web -- an Overview
Mar 12, 2020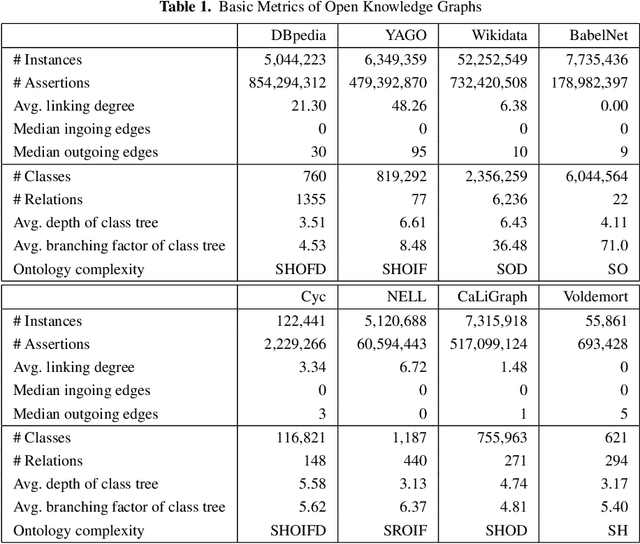
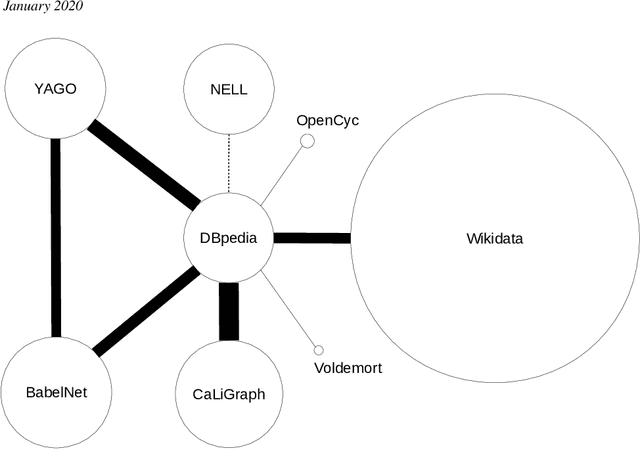
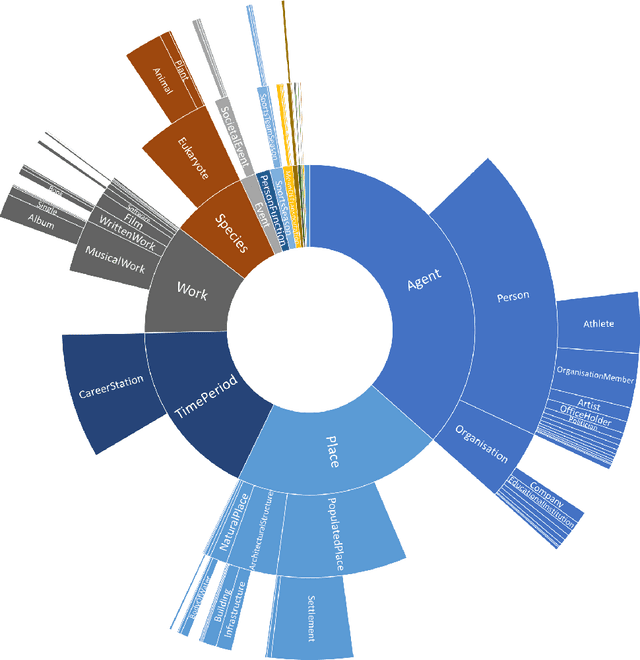
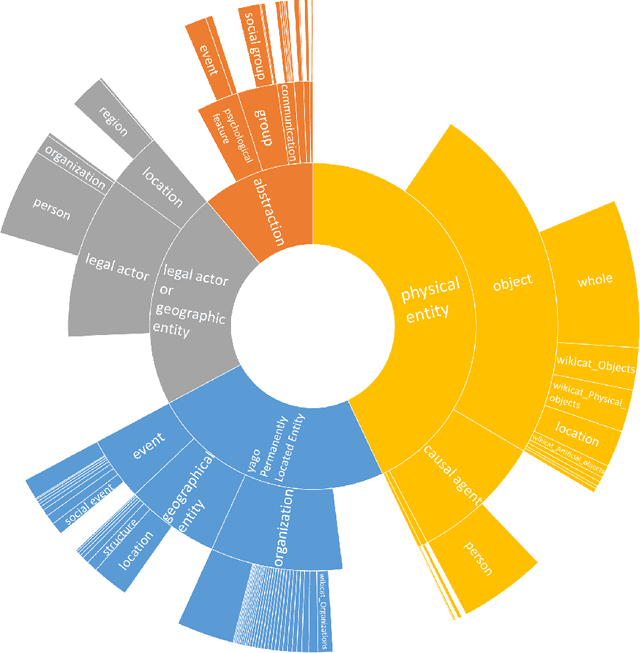
Knowledge Graphs are an emerging form of knowledge representation. While Google coined the term Knowledge Graph first and promoted it as a means to improve their search results, they are used in many applications today. In a knowledge graph, entities in the real world and/or a business domain (e.g., people, places, or events) are represented as nodes, which are connected by edges representing the relations between those entities. While companies such as Google, Microsoft, and Facebook have their own, non-public knowledge graphs, there is also a larger body of publicly available knowledge graphs, such as DBpedia or Wikidata. In this chapter, we provide an overview and comparison of those publicly available knowledge graphs, and give insights into their contents, size, coverage, and overlap.
Entity Extraction from Wikipedia List Pages
Mar 11, 2020
When it comes to factual knowledge about a wide range of domains, Wikipedia is often the prime source of information on the web. DBpedia and YAGO, as large cross-domain knowledge graphs, encode a subset of that knowledge by creating an entity for each page in Wikipedia, and connecting them through edges. It is well known, however, that Wikipedia-based knowledge graphs are far from complete. Especially, as Wikipedia's policies permit pages about subjects only if they have a certain popularity, such graphs tend to lack information about less well-known entities. Information about these entities is oftentimes available in the encyclopedia, but not represented as an individual page. In this paper, we present a two-phased approach for the extraction of entities from Wikipedia's list pages, which have proven to serve as a valuable source of information. In the first phase, we build a large taxonomy from categories and list pages with DBpedia as a backbone. With distant supervision, we extract training data for the identification of new entities in list pages that we use in the second phase to train a classification model. With this approach we extract over 700k new entities and extend DBpedia with 7.5M new type statements and 3.8M new facts of high precision.
Uncovering the Semantics of Wikipedia Categories
Jun 28, 2019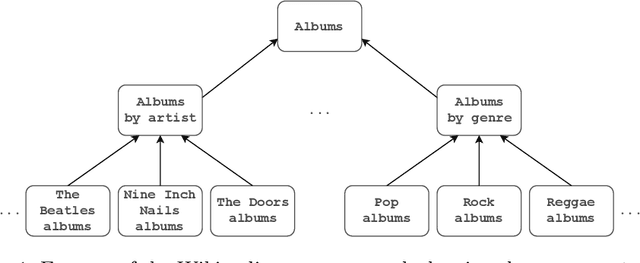
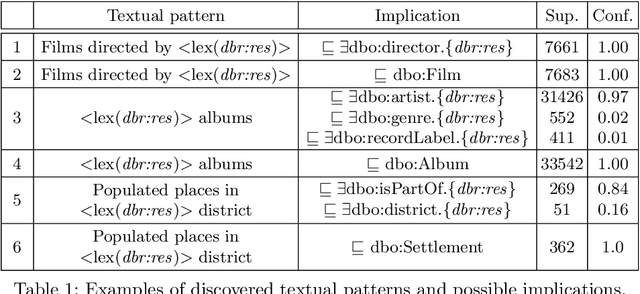
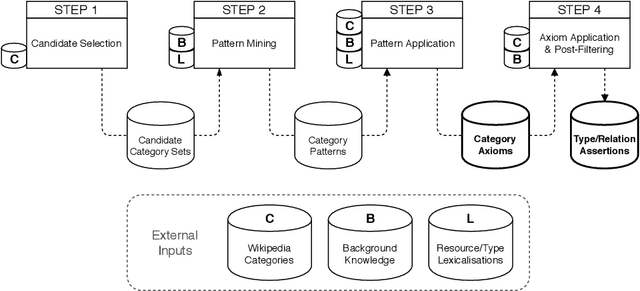
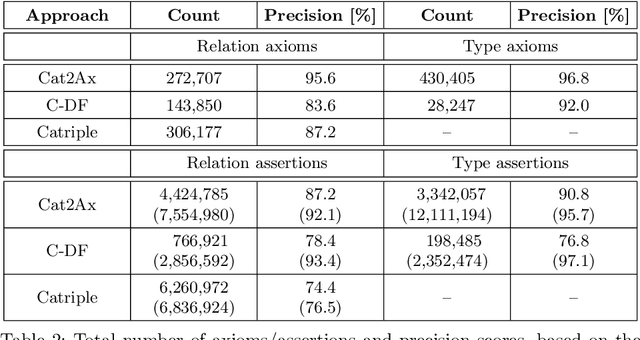
The Wikipedia category graph serves as the taxonomic backbone for large-scale knowledge graphs like YAGO or Probase, and has been used extensively for tasks like entity disambiguation or semantic similarity estimation. Wikipedia's categories are a rich source of taxonomic as well as non-taxonomic information. The category 'German science fiction writers', for example, encodes the type of its resources (Writer), as well as their nationality (German) and genre (Science Fiction). Several approaches in the literature make use of fractions of this encoded information without exploiting its full potential. In this paper, we introduce an approach for the discovery of category axioms that uses information from the category network, category instances, and their lexicalisations. With DBpedia as background knowledge, we discover 703k axioms covering 502k of Wikipedia's categories and populate the DBpedia knowledge graph with additional 4.4M relation assertions and 3.3M type assertions at more than 87% and 90% precision, respectively.