 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOntology Matching Through Absolute Orientation of Embedding Spaces
Apr 08, 2022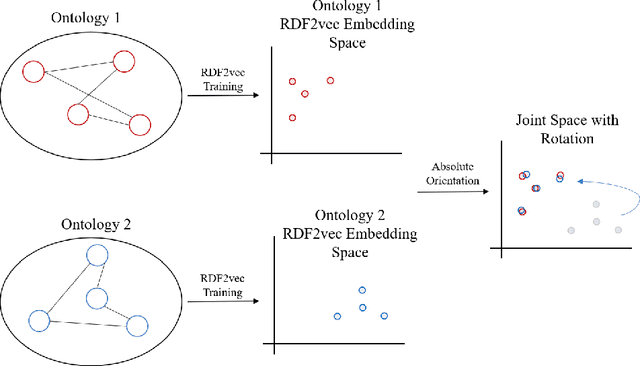
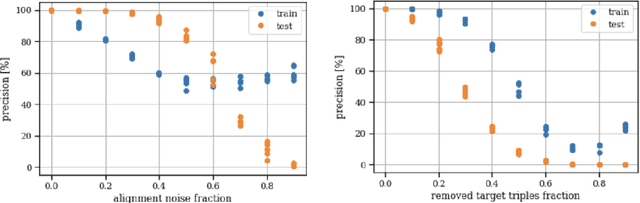
Ontology matching is a core task when creating interoperable and linked open datasets. In this paper, we explore a novel structure-based mapping approach which is based on knowledge graph embeddings: The ontologies to be matched are embedded, and an approach known as absolute orientation is used to align the two embedding spaces. Next to the approach, the paper presents a first, preliminary evaluation using synthetic and real-world datasets. We find in experiments with synthetic data, that the approach works very well on similarly structured graphs; it handles alignment noise better than size and structural differences in the ontologies.
Background Knowledge in Schema Matching: Strategy vs. Data
Jun 29, 2021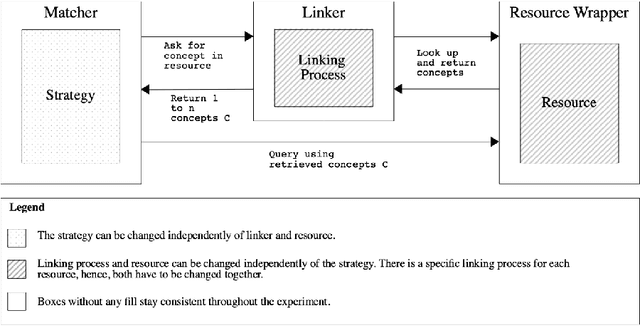
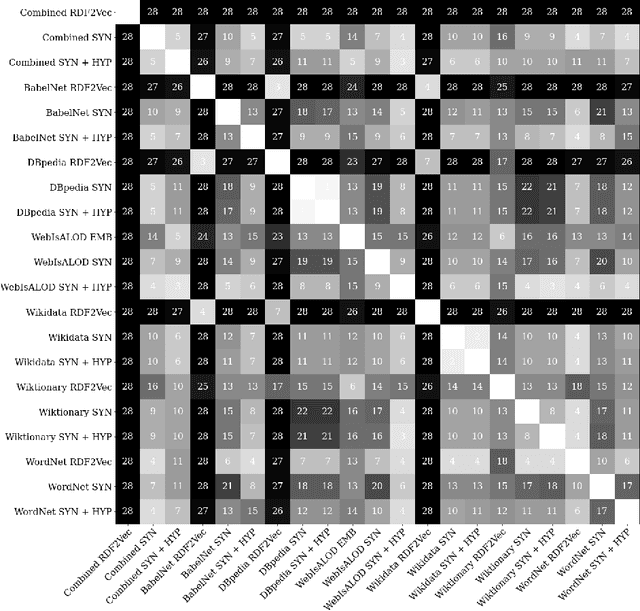
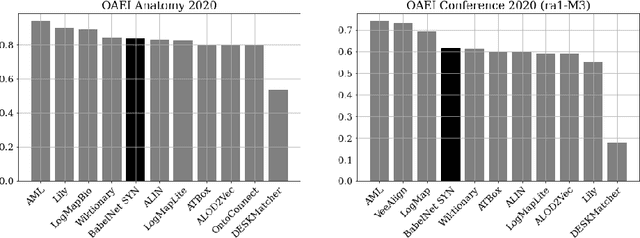
The use of external background knowledge can be beneficial for the task of matching schemas or ontologies automatically. In this paper, we exploit six general-purpose knowledge graphs as sources of background knowledge for the matching task. The background sources are evaluated by applying three different exploitation strategies. We find that explicit strategies still outperform latent ones and that the choice of the strategy has a greater impact on the final alignment than the actual background dataset on which the strategy is applied. While we could not identify a universally superior resource, BabelNet achieved consistently good results. Our best matcher configuration with BabelNet performs very competitively when compared to other matching systems even though no dataset-specific optimizations were made.
FinMatcher at FinSim-2: Hypernym Detection in the Financial Services Domain using Knowledge Graphs
Mar 02, 2021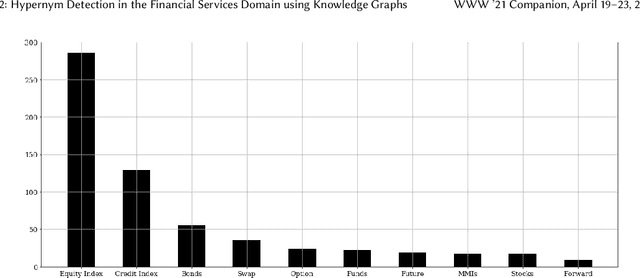
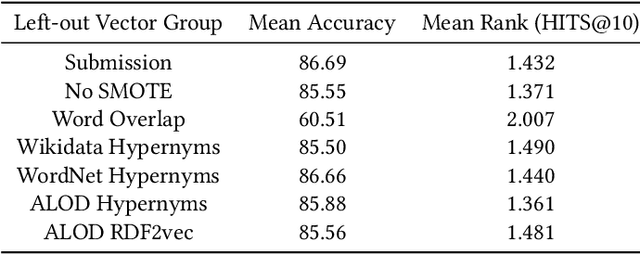
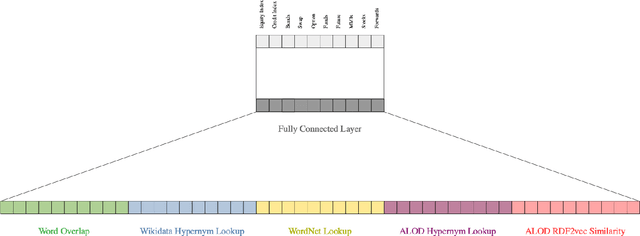
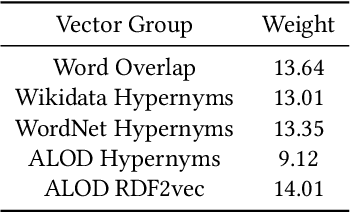
This paper presents the FinMatcher system and its results for the FinSim 2021 shared task which is co-located with the Workshop on Financial Technology on the Web (FinWeb) in conjunction with The Web Conference. The FinSim-2 shared task consists of a set of concept labels from the financial services domain. The goal is to find the most relevant top-level concept from a given set of concepts. The FinMatcher system exploits three publicly available knowledge graphs, namely WordNet, Wikidata, and WebIsALOD. The graphs are used to generate explicit features as well as latent features which are fed into a neural classifier to predict the closest hypernym.
RDF2Vec Light -- A Lightweight Approach for Knowledge Graph Embeddings
Sep 17, 2020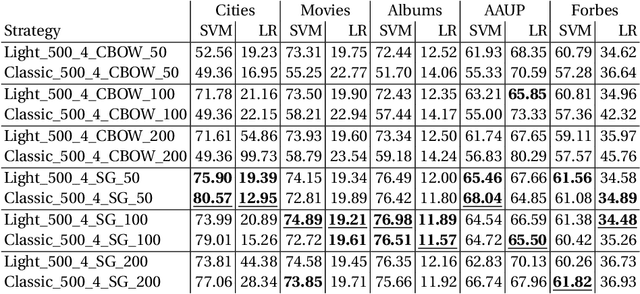

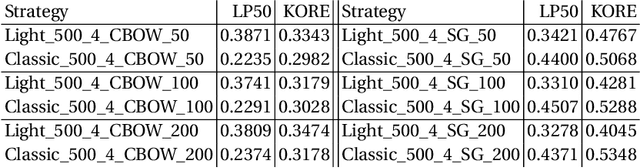
Knowledge graph embedding approaches represent nodes and edges of graphs as mathematical vectors. Current approaches focus on embedding complete knowledge graphs, i.e. all nodes and edges. This leads to very high computational requirements on large graphs such as DBpedia or Wikidata. However, for most downstream application scenarios, only a small subset of concepts is of actual interest. In this paper, we present RDF2Vec Light, a lightweight embedding approach based on RDF2Vec which generates vectors for only a subset of entities. To that end, RDF2Vec Light only traverses and processes a subgraph of the knowledge graph. Our method allows the application of embeddings of very large knowledge graphs in scenarios where such embeddings were not possible before due to a significantly lower runtime and significantly reduced hardware requirements.
KGvec2go -- Knowledge Graph Embeddings as a Service
Mar 09, 2020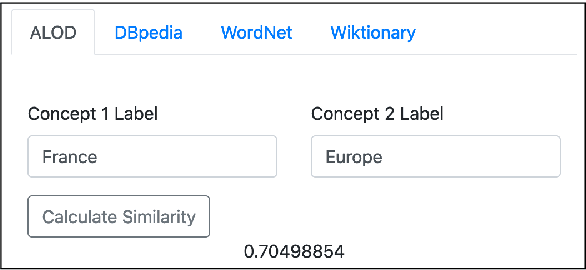
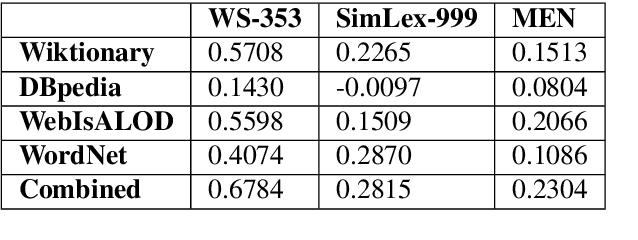
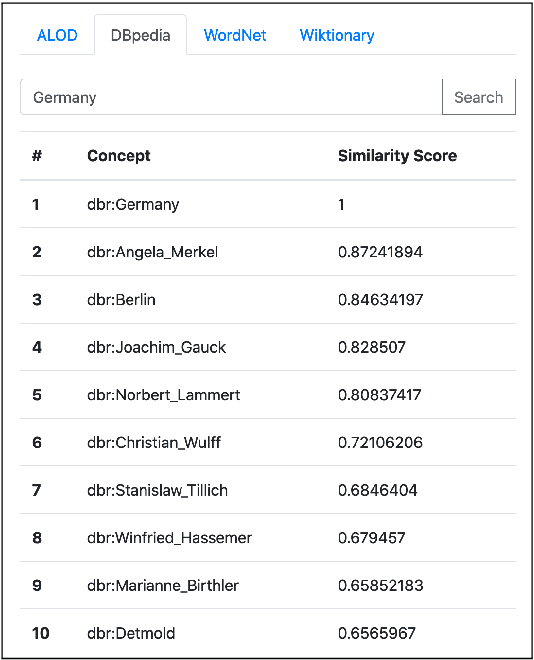
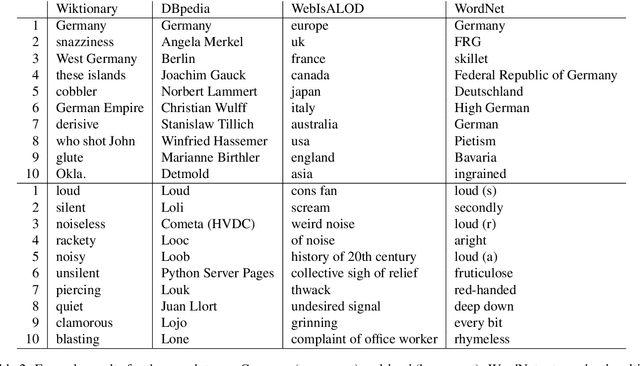
In this paper, we present KGvec2go, a Web API for accessing and consuming graph embeddings in a light-weight fashion in downstream applications. Currently, we serve pre-trained embeddings for four knowledge graphs. We introduce the service and its usage, and we show further that the trained models have semantic value by evaluating them on multiple semantic benchmarks. The evaluation also reveals that the combination of multiple models can lead to a better outcome than the best individual model.