 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackground Knowledge in Schema Matching: Strategy vs. Data
Paper and Code
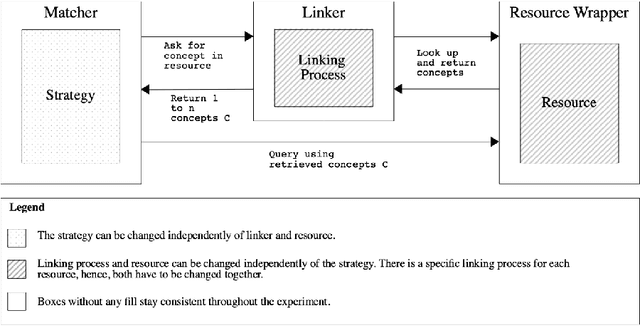
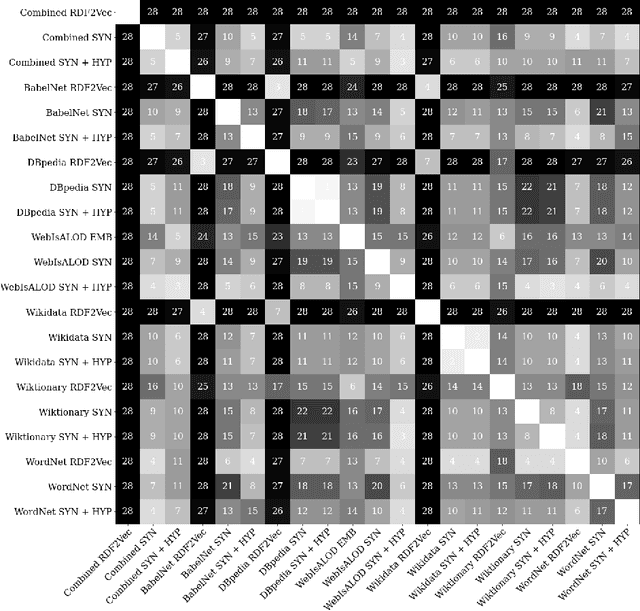
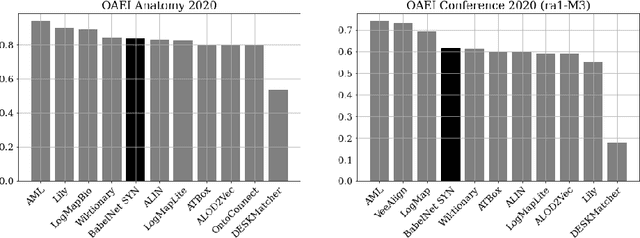
The use of external background knowledge can be beneficial for the task of matching schemas or ontologies automatically. In this paper, we exploit six general-purpose knowledge graphs as sources of background knowledge for the matching task. The background sources are evaluated by applying three different exploitation strategies. We find that explicit strategies still outperform latent ones and that the choice of the strategy has a greater impact on the final alignment than the actual background dataset on which the strategy is applied. While we could not identify a universally superior resource, BabelNet achieved consistently good results. Our best matcher configuration with BabelNet performs very competitively when compared to other matching systems even though no dataset-specific optimizations were made.