 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEntity Type Prediction in Knowledge Graphs using Embeddings
May 06, 2020
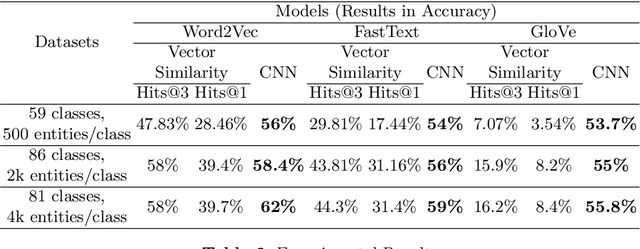
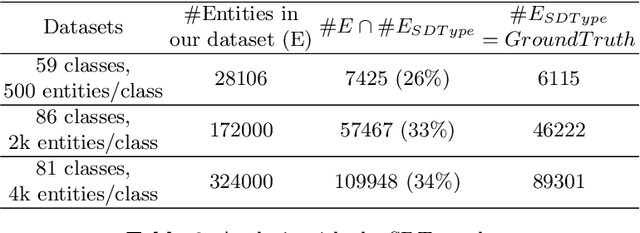
Open Knowledge Graphs (such as DBpedia, Wikidata, YAGO) have been recognized as the backbone of diverse applications in the field of data mining and information retrieval. Hence, the completeness and correctness of the Knowledge Graphs (KGs) are vital. Most of these KGs are mostly created either via an automated information extraction from Wikipedia snapshots or information accumulation provided by the users or using heuristics. However, it has been observed that the type information of these KGs is often noisy, incomplete, and incorrect. To deal with this problem a multi-label classification approach is proposed in this work for entity typing using KG embeddings. We compare our approach with the current state-of-the-art type prediction method and report on experiments with the KGs.