 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Spatial-Temporal Learner for Precipitation Nowcasting
Dec 20, 2024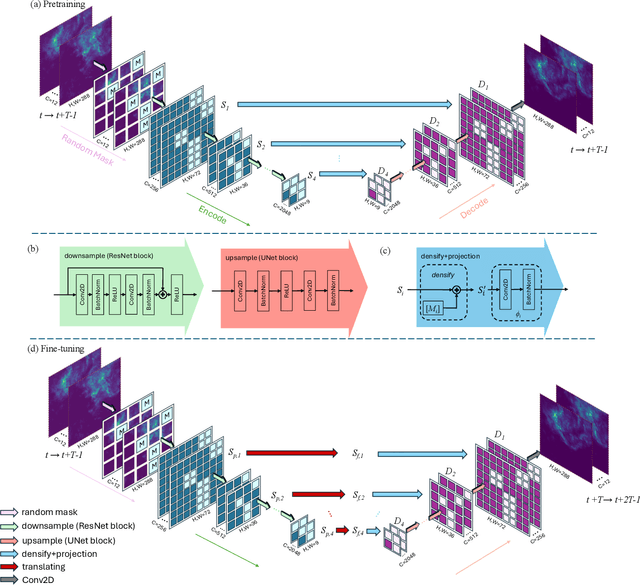
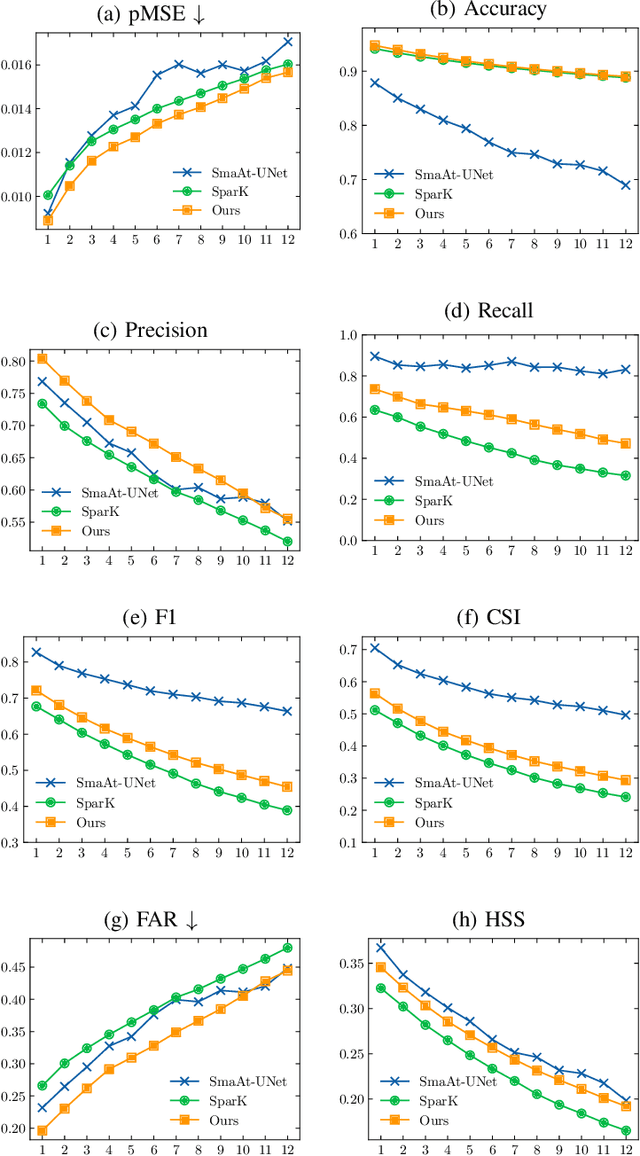
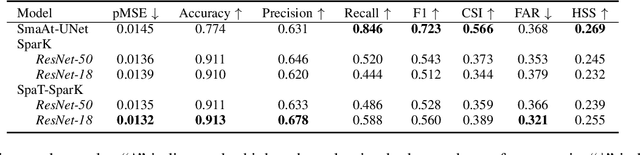

Nowcasting, the short-term prediction of weather, is essential for making timely and weather-dependent decisions. Specifically, precipitation nowcasting aims to predict precipitation at a local level within a 6-hour time frame. This task can be framed as a spatial-temporal sequence forecasting problem, where deep learning methods have been particularly effective. However, despite advancements in self-supervised learning, most successful methods for nowcasting remain fully supervised. Self-supervised learning is advantageous for pretraining models to learn representations without requiring extensive labeled data. In this work, we leverage the benefits of self-supervised learning and integrate it with spatial-temporal learning to develop a novel model, SpaT-SparK. SpaT-SparK comprises a CNN-based encoder-decoder structure pretrained with a masked image modeling (MIM) task and a translation network that captures temporal relationships among past and future precipitation maps in downstream tasks. We conducted experiments on the NL-50 dataset to evaluate the performance of SpaT-SparK. The results demonstrate that SpaT-SparK outperforms existing baseline supervised models, such as SmaAt-UNet, providing more accurate nowcasting predictions.
Identifying Predictions That Influence the Future: Detecting Performative Concept Drift in Data Streams
Dec 13, 2024



Concept Drift has been extensively studied within the context of Stream Learning. However, it is often assumed that the deployed model's predictions play no role in the concept drift the system experiences. Closer inspection reveals that this is not always the case. Automated trading might be prone to self-fulfilling feedback loops. Likewise, malicious entities might adapt to evade detectors in the adversarial setting resulting in a self-negating feedback loop that requires the deployed models to constantly retrain. Such settings where a model may induce concept drift are called performative. In this work, we investigate this phenomenon. Our contributions are as follows: First, we define performative drift within a stream learning setting and distinguish it from other causes of drift. We introduce a novel type of drift detection task, aimed at identifying potential performative concept drift in data streams. We propose a first such performative drift detection approach, called CheckerBoard Performative Drift Detection (CB-PDD). We apply CB-PDD to both synthetic and semi-synthetic datasets that exhibit varying degrees of self-fulfilling feedback loops. Results are positive with CB-PDD showing high efficacy, low false detection rates, resilience to intrinsic drift, comparability to other drift detection techniques, and an ability to effectively detect performative drift in semi-synthetic datasets. Secondly, we highlight the role intrinsic (traditional) drift plays in obfuscating performative drift and discuss the implications of these findings as well as the limitations of CB-PDD.
Keeping it Short and Simple: Summarising Complex Event Sequences with Multivariate Patterns
Feb 10, 2016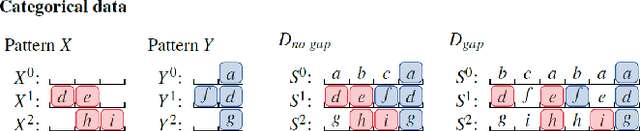
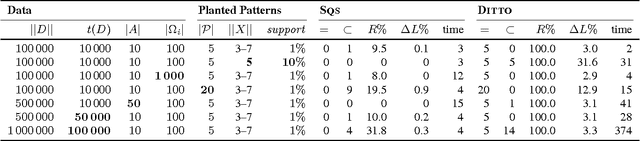
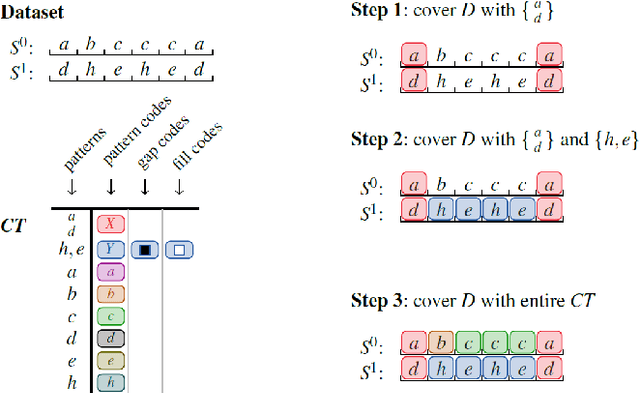

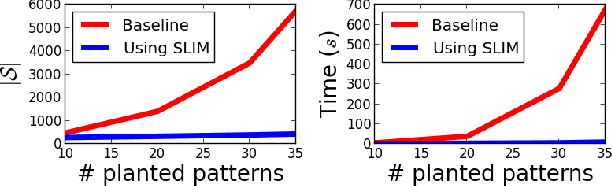
We study how to obtain concise descriptions of discrete multivariate sequential data. In particular, how to do so in terms of rich multivariate sequential patterns that can capture potentially highly interesting (cor)relations between sequences. To this end we allow our pattern language to span over the domains (alphabets) of all sequences, allow patterns to overlap temporally, as well as allow for gaps in their occurrences. We formalise our goal by the Minimum Description Length principle, by which our objective is to discover the set of patterns that provides the most succinct description of the data. To discover high-quality pattern sets directly from data, we introduce DITTO, a highly efficient algorithm that approximates the ideal result very well. Experiments show that DITTO correctly discovers the patterns planted in synthetic data. Moreover, it scales favourably with the length of the data, the number of attributes, the alphabet sizes. On real data, ranging from sensor networks to annotated text, DITTO discovers easily interpretable summaries that provide clear insight in both the univariate and multivariate structure.
Beauty and Brains: Detecting Anomalous Pattern Co-Occurrences
Feb 10, 2016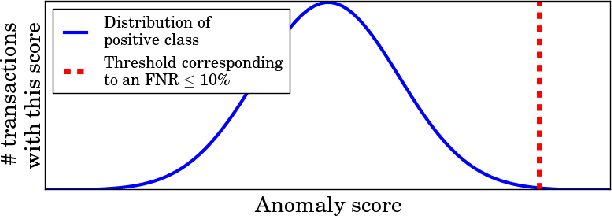
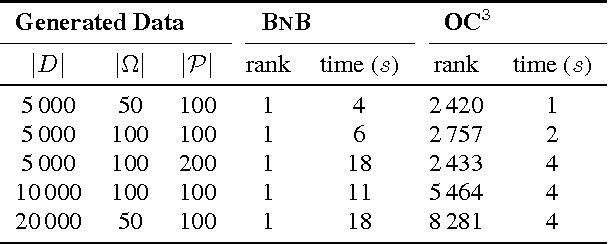
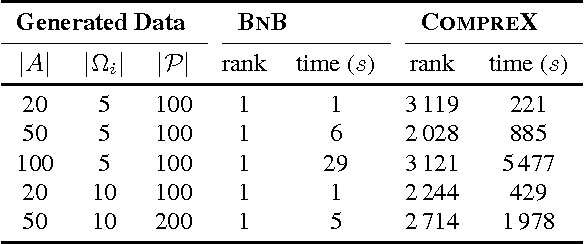
Our world is filled with both beautiful and brainy people, but how often does a Nobel Prize winner also wins a beauty pageant? Let us assume that someone who is both very beautiful and very smart is more rare than what we would expect from the combination of the number of beautiful and brainy people. Of course there will still always be some individuals that defy this stereotype; these beautiful brainy people are exactly the class of anomaly we focus on in this paper. They do not posses intrinsically rare qualities, it is the unexpected combination of factors that makes them stand out. In this paper we define the above described class of anomaly and propose a method to quickly identify them in transaction data. Further, as we take a pattern set based approach, our method readily explains why a transaction is anomalous. The effectiveness of our method is thoroughly verified with a wide range of experiments on both real world and synthetic data.