 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequence Shortening for Context-Aware Machine Translation
Paper and Code
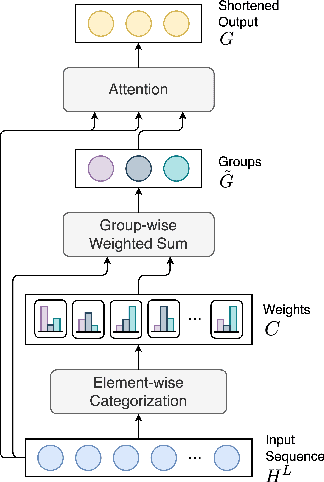



Context-aware Machine Translation aims to improve translations of sentences by incorporating surrounding sentences as context. Towards this task, two main architectures have been applied, namely single-encoder (based on concatenation) and multi-encoder models. In this study, we show that a special case of multi-encoder architecture, where the latent representation of the source sentence is cached and reused as the context in the next step, achieves higher accuracy on the contrastive datasets (where the models have to rank the correct translation among the provided sentences) and comparable BLEU and COMET scores as the single- and multi-encoder approaches. Furthermore, we investigate the application of Sequence Shortening to the cached representations. We test three pooling-based shortening techniques and introduce two novel methods - Latent Grouping and Latent Selecting, where the network learns to group tokens or selects the tokens to be cached as context. Our experiments show that the two methods achieve competitive BLEU and COMET scores and accuracies on the contrastive datasets to the other tested methods while potentially allowing for higher interpretability and reducing the growth of memory requirements with increased context size.