Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Two Sides of the Coin: Hallucination Generation and Detection with LLMs as Evaluators for LLMs
Jul 12, 2024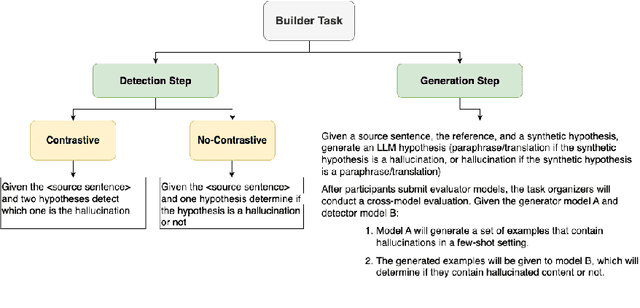

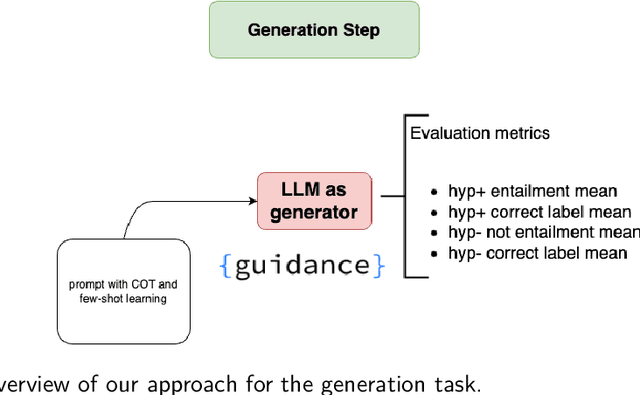

Hallucination detection in Large Language Models (LLMs) is crucial for ensuring their reliability. This work presents our participation in the CLEF ELOQUENT HalluciGen shared task, where the goal is to develop evaluators for both generating and detecting hallucinated content. We explored the capabilities of four LLMs: Llama 3, Gemma, GPT-3.5 Turbo, and GPT-4, for this purpose. We also employed ensemble majority voting to incorporate all four models for the detection task. The results provide valuable insights into the strengths and weaknesses of these LLMs in handling hallucination generation and detection tasks.
* Paper accepted at ELOQUENT@CLEF'24
Via