 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning from LDA to BiLSTM-CNN for Offensive Language Detection in Twitter
Nov 07, 2018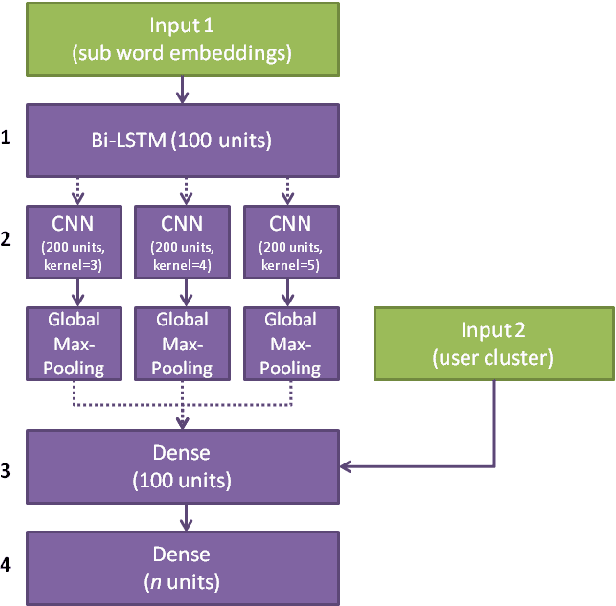

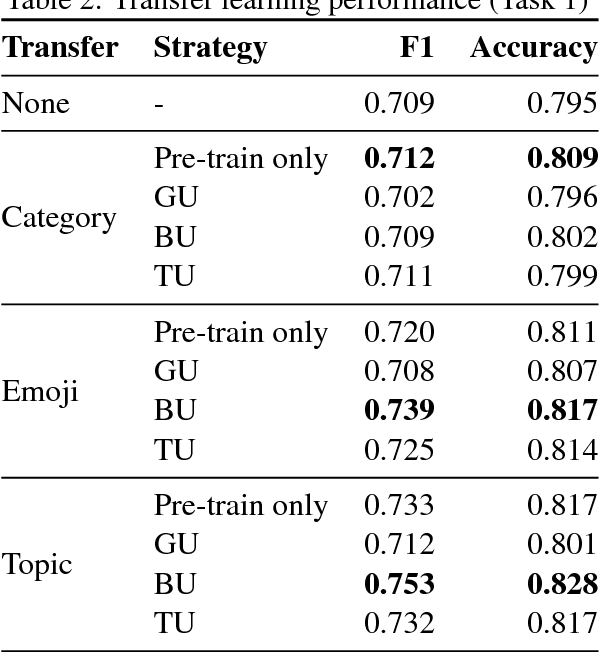
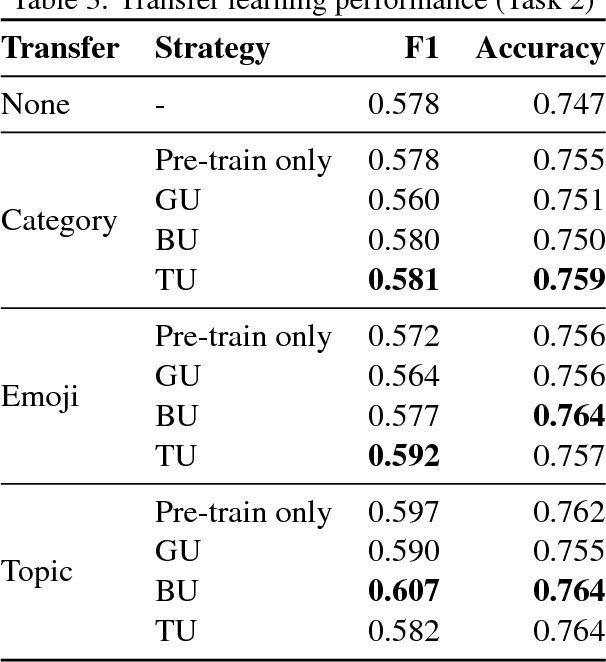
We investigate different strategies for automatic offensive language classification on German Twitter data. For this, we employ a sequentially combined BiLSTM-CNN neural network. Based on this model, three transfer learning tasks to improve the classification performance with background knowledge are tested. We compare 1. Supervised category transfer: social media data annotated with near-offensive language categories, 2. Weakly-supervised category transfer: tweets annotated with emojis they contain, 3. Unsupervised category transfer: tweets annotated with topic clusters obtained by Latent Dirichlet Allocation (LDA). Further, we investigate the effect of three different strategies to mitigate negative effects of 'catastrophic forgetting' during transfer learning. Our results indicate that transfer learning in general improves offensive language detection. Best results are achieved from pre-training our model on the unsupervised topic clustering of tweets in combination with thematic user cluster information.
* 10 pages, 1 figure
Building a Web-Scale Dependency-Parsed Corpus from CommonCrawl
Feb 28, 2018


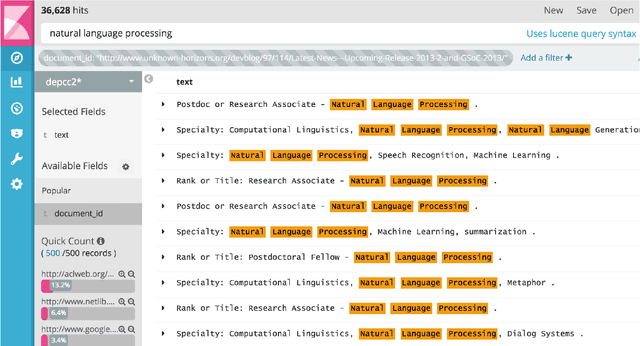
We present DepCC, the largest-to-date linguistically analyzed corpus in English including 365 million documents, composed of 252 billion tokens and 7.5 billion of named entity occurrences in 14.3 billion sentences from a web-scale crawl of the \textsc{Common Crawl} project. The sentences are processed with a dependency parser and with a named entity tagger and contain provenance information, enabling various applications ranging from training syntax-based word embeddings to open information extraction and question answering. We built an index of all sentences and their linguistic meta-data enabling quick search across the corpus. We demonstrate the utility of this corpus on the verb similarity task by showing that a distributional model trained on our corpus yields better results than models trained on smaller corpora, like Wikipedia. This distributional model outperforms the state of art models of verb similarity trained on smaller corpora on the SimVerb3500 dataset.
Unsupervised, Knowledge-Free, and Interpretable Word Sense Disambiguation
Jul 21, 2017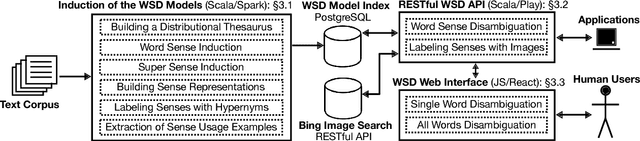
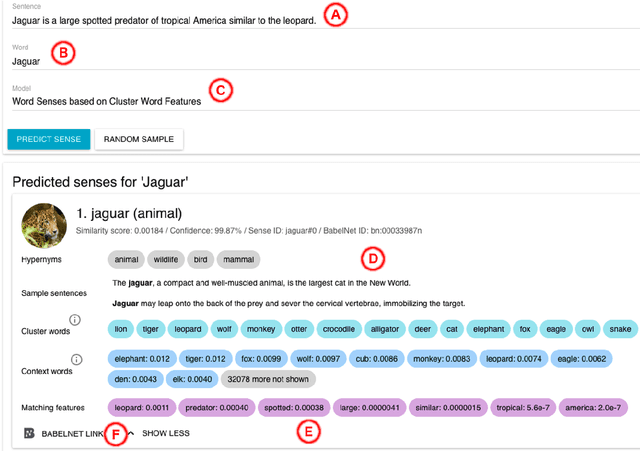

Interpretability of a predictive model is a powerful feature that gains the trust of users in the correctness of the predictions. In word sense disambiguation (WSD), knowledge-based systems tend to be much more interpretable than knowledge-free counterparts as they rely on the wealth of manually-encoded elements representing word senses, such as hypernyms, usage examples, and images. We present a WSD system that bridges the gap between these two so far disconnected groups of methods. Namely, our system, providing access to several state-of-the-art WSD models, aims to be interpretable as a knowledge-based system while it remains completely unsupervised and knowledge-free. The presented tool features a Web interface for all-word disambiguation of texts that makes the sense predictions human readable by providing interpretable word sense inventories, sense representations, and disambiguation results. We provide a public API, enabling seamless integration.