 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning from LDA to BiLSTM-CNN for Offensive Language Detection in Twitter
Nov 07, 2018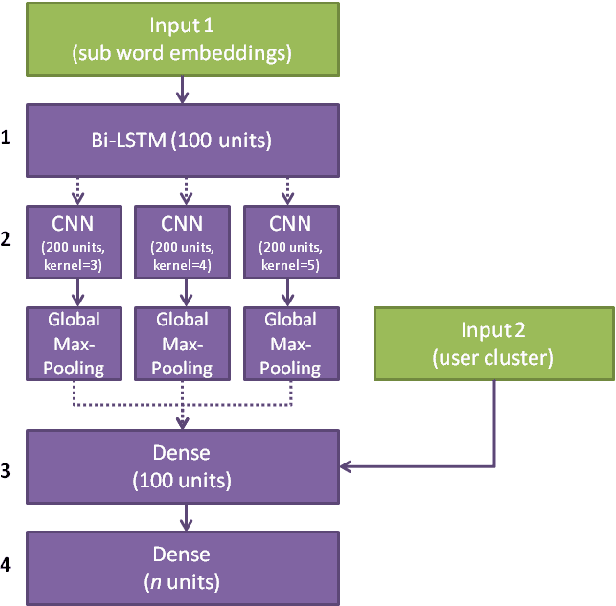

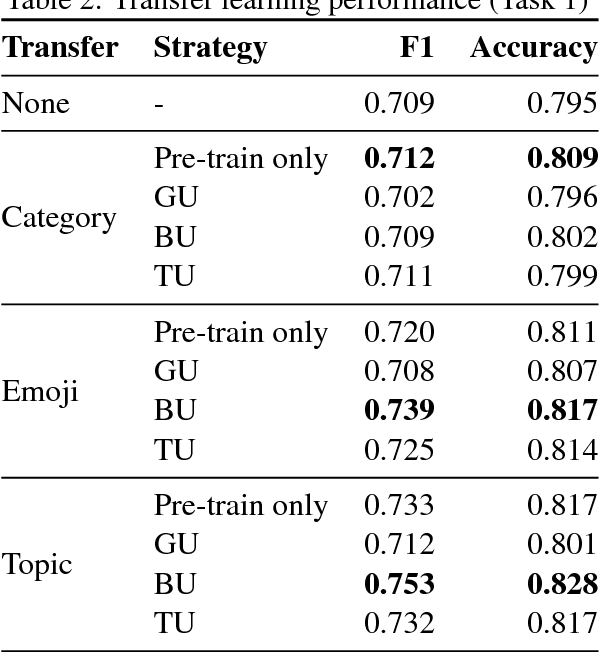
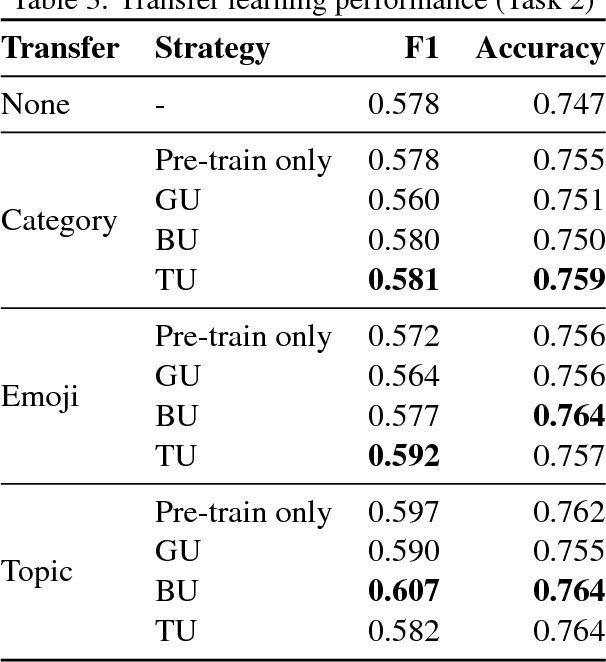
We investigate different strategies for automatic offensive language classification on German Twitter data. For this, we employ a sequentially combined BiLSTM-CNN neural network. Based on this model, three transfer learning tasks to improve the classification performance with background knowledge are tested. We compare 1. Supervised category transfer: social media data annotated with near-offensive language categories, 2. Weakly-supervised category transfer: tweets annotated with emojis they contain, 3. Unsupervised category transfer: tweets annotated with topic clusters obtained by Latent Dirichlet Allocation (LDA). Further, we investigate the effect of three different strategies to mitigate negative effects of 'catastrophic forgetting' during transfer learning. Our results indicate that transfer learning in general improves offensive language detection. Best results are achieved from pre-training our model on the unsupervised topic clustering of tweets in combination with thematic user cluster information.
* 10 pages, 1 figure
microNER: A Micro-Service for German Named Entity Recognition based on BiLSTM-CRF
Nov 07, 2018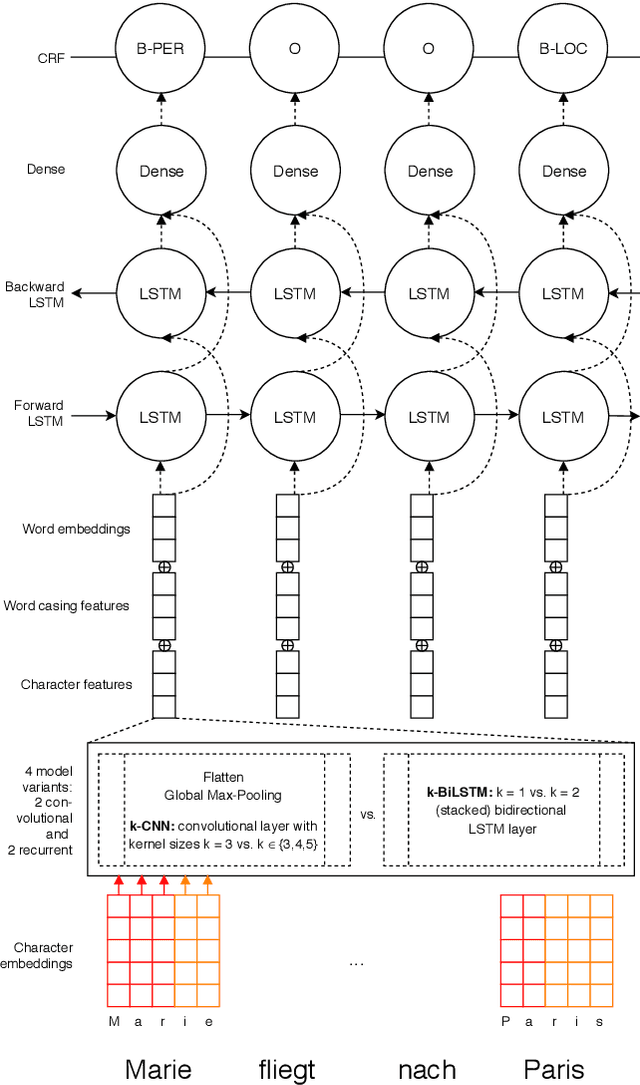
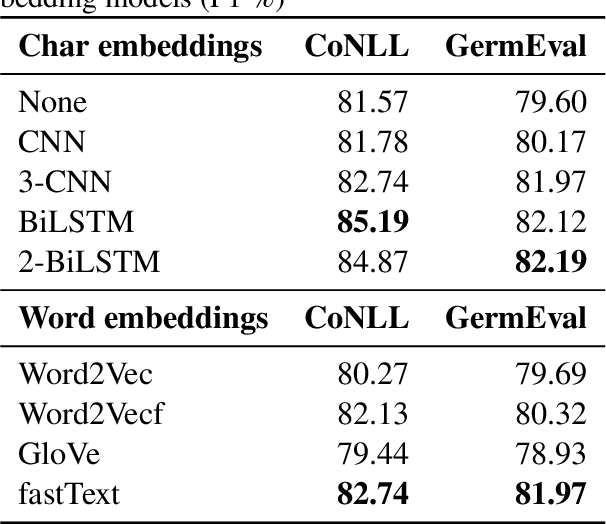
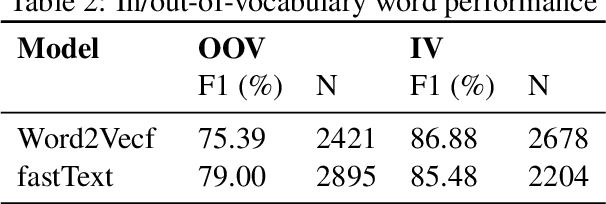
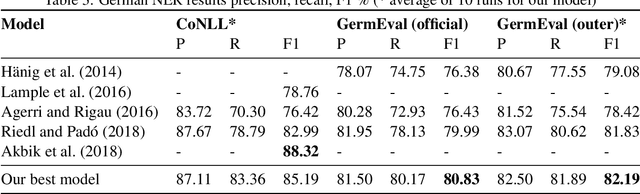
For named entity recognition (NER), bidirectional recurrent neural networks became the state-of-the-art technology in recent years. Competing approaches vary with respect to pre-trained word embeddings as well as models for character embeddings to represent sequence information most effectively. For NER in German language texts, these model variations have not been studied extensively. We evaluate the performance of different word and character embeddings on two standard German datasets and with a special focus on out-of-vocabulary words. With F-Scores above 82% for the GermEval'14 dataset and above 85% for the CoNLL'03 dataset, we achieve (near) state-of-the-art performance for this task. We publish several pre-trained models wrapped into a micro-service based on Docker to allow for easy integration of German NER into other applications via a JSON API.
* 7 pages, 1 figure