 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scalable Approach to Covariate and Concept Drift Management via Adaptive Data Segmentation
Nov 23, 2024
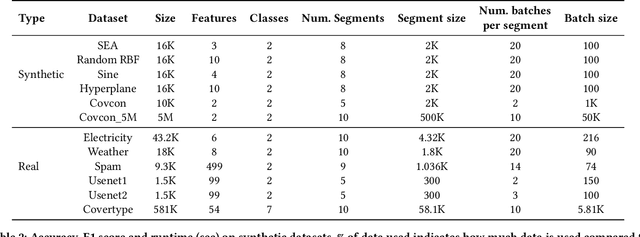


In many real-world applications, continuous machine learning (ML) systems are crucial but prone to data drift, a phenomenon where discrepancies between historical training data and future test data lead to significant performance degradation and operational inefficiencies. Traditional drift adaptation methods typically update models using ensemble techniques, often discarding drifted historical data, and focus primarily on either covariate drift or concept drift. These methods face issues such as high resource demands, inability to manage all types of drifts effectively, and neglecting the valuable context that historical data can provide. We contend that explicitly incorporating drifted data into the model training process significantly enhances model accuracy and robustness. This paper introduces an advanced framework that integrates the strengths of data-centric approaches with adaptive management of both covariate and concept drift in a scalable and efficient manner. Our framework employs sophisticated data segmentation techniques to identify optimal data batches that accurately reflect test data patterns. These data batches are then utilized for training on test data, ensuring that the models remain relevant and accurate over time. By leveraging the advantages of both data segmentation and scalable drift management, our solution ensures robust model accuracy and operational efficiency in large-scale ML deployments. It also minimizes resource consumption and computational overhead by selecting and utilizing relevant data subsets, leading to significant cost savings. Experimental results on classification task on real-world and synthetic datasets show our approach improves model accuracy while reducing operational costs and latency. This practical solution overcomes inefficiencies in current methods, providing a robust, adaptable, and scalable approach.
Modeling Inter-Dependence Between Time and Mark in Multivariate Temporal Point Processes
Oct 27, 2022Temporal Point Processes (TPP) are probabilistic generative frameworks. They model discrete event sequences localized in continuous time. Generally, real-life events reveal descriptive information, known as marks. Marked TPPs model time and marks of the event together for practical relevance. Conditioned on past events, marked TPPs aim to learn the joint distribution of the time and the mark of the next event. For simplicity, conditionally independent TPP models assume time and marks are independent given event history. They factorize the conditional joint distribution of time and mark into the product of individual conditional distributions. This structural limitation in the design of TPP models hurt the predictive performance on entangled time and mark interactions. In this work, we model the conditional inter-dependence of time and mark to overcome the limitations of conditionally independent models. We construct a multivariate TPP conditioning the time distribution on the current event mark in addition to past events. Besides the conventional intensity-based models for conditional joint distribution, we also draw on flexible intensity-free TPP models from the literature. The proposed TPP models outperform conditionally independent and dependent models in standard prediction tasks. Our experimentation on various datasets with multiple evaluation metrics highlights the merit of the proposed approach.