 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRANSPR: Transparency Ray-Accumulating Neural 3D Scene Point Renderer
Paper and Code
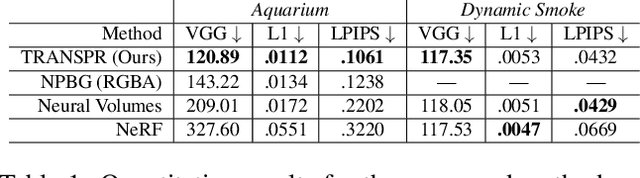
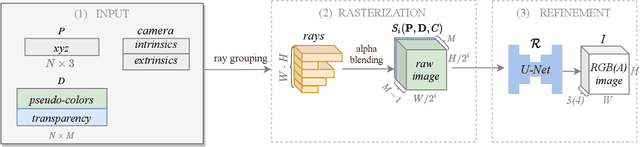
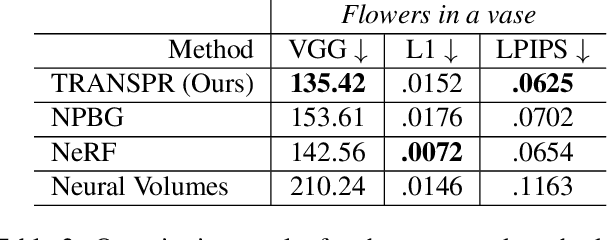
We propose and evaluate a neural point-based graphics method that can model semi-transparent scene parts. Similarly to its predecessor pipeline, ours uses point clouds to model proxy geometry, and augments each point with a neural descriptor. Additionally, a learnable transparency value is introduced in our approach for each point. Our neural rendering procedure consists of two steps. Firstly, the point cloud is rasterized using ray grouping into a multi-channel image. This is followed by the neural rendering step that "translates" the rasterized image into an RGB output using a learnable convolutional network. New scenes can be modeled using gradient-based optimization of neural descriptors and of the rendering network. We show that novel views of semi-transparent point cloud scenes can be generated after training with our approach. Our experiments demonstrate the benefit of introducing semi-transparency into the neural point-based modeling for a range of scenes with semi-transparent parts.