 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs as annotators of credibility assessment in Danish asylum decisions: evaluating classification performance and errors beyond aggregated metrics
May 13, 2026Off-the-shelf large language models (LLMs) are increasingly used to automate text annotation, yet their effectiveness remains underexplored for underrepresented languages and specialized domains where the class definition requires subtle expert understanding. We investigate LLM-based annotation for a novel legal NLP task: identifying the presence and sentiment of credibility assessments in asylum decision texts. We introduce RAB-Cred, a Danish text classification dataset featuring high-quality, expert annotations and valuable metadata such as annotator confidence and asylum case outcome. We benchmark 21 open-weight models and 30 system-user prompt combinations for this task, and systematically evaluate the effect of model and prompt choice for zero-shot and few-shot classification. We zoom in on the errors made by top-performing models and prompts, investigating error consistency across LLMs, inter-class confusion, correlation with human confidence and sample-wise difficulty and severity of LLM mistakes. Our results confirm the potential of LLMs for cost-effective labeling of asylum decisions, but highlight the imperfect and inconsistent nature of LLM annotators, and the need to look beyond the predictions of a single, arbitrarily chosen model. The RAB-Cred dataset and code are available at https://github.com/glhr/RAB-Cred
COOkeD: Ensemble-based OOD detection in the era of zero-shot CLIP
Jul 30, 2025Out-of-distribution (OOD) detection is an important building block in trustworthy image recognition systems as unknown classes may arise at test-time. OOD detection methods typically revolve around a single classifier, leading to a split in the research field between the classical supervised setting (e.g. ResNet18 classifier trained on CIFAR100) vs. the zero-shot setting (class names fed as prompts to CLIP). In both cases, an overarching challenge is that the OOD detection performance is implicitly constrained by the classifier's capabilities on in-distribution (ID) data. In this work, we show that given a little open-mindedness from both ends, remarkable OOD detection can be achieved by instead creating a heterogeneous ensemble - COOkeD combines the predictions of a closed-world classifier trained end-to-end on a specific dataset, a zero-shot CLIP classifier, and a linear probe classifier trained on CLIP image features. While bulky at first sight, this approach is modular, post-hoc and leverages the availability of pre-trained VLMs, thus introduces little overhead compared to training a single standard classifier. We evaluate COOkeD on popular CIFAR100 and ImageNet benchmarks, but also consider more challenging, realistic settings ranging from training-time label noise, to test-time covariate shift, to zero-shot shift which has been previously overlooked. Despite its simplicity, COOkeD achieves state-of-the-art performance and greater robustness compared to both classical and CLIP-based OOD detection methods. Code is available at https://github.com/glhr/COOkeD
A noisy elephant in the room: Is your out-of-distribution detector robust to label noise?
Apr 02, 2024The ability to detect unfamiliar or unexpected images is essential for safe deployment of computer vision systems. In the context of classification, the task of detecting images outside of a model's training domain is known as out-of-distribution (OOD) detection. While there has been a growing research interest in developing post-hoc OOD detection methods, there has been comparably little discussion around how these methods perform when the underlying classifier is not trained on a clean, carefully curated dataset. In this work, we take a closer look at 20 state-of-the-art OOD detection methods in the (more realistic) scenario where the labels used to train the underlying classifier are unreliable (e.g. crowd-sourced or web-scraped labels). Extensive experiments across different datasets, noise types & levels, architectures and checkpointing strategies provide insights into the effect of class label noise on OOD detection, and show that poor separation between incorrectly classified ID samples vs. OOD samples is an overlooked yet important limitation of existing methods. Code: https://github.com/glhr/ood-labelnoise
Beyond AUROC & co. for evaluating out-of-distribution detection performance
Jun 26, 2023While there has been a growing research interest in developing out-of-distribution (OOD) detection methods, there has been comparably little discussion around how these methods should be evaluated. Given their relevance for safe(r) AI, it is important to examine whether the basis for comparing OOD detection methods is consistent with practical needs. In this work, we take a closer look at the go-to metrics for evaluating OOD detection, and question the approach of exclusively reducing OOD detection to a binary classification task with little consideration for the detection threshold. We illustrate the limitations of current metrics (AUROC & its friends) and propose a new metric - Area Under the Threshold Curve (AUTC), which explicitly penalizes poor separation between ID and OOD samples. Scripts and data are available at https://github.com/glhr/beyond-auroc
From CAD models to soft point cloud labels: An automatic annotation pipeline for cheaply supervised 3D semantic segmentation
Feb 06, 2023We propose a fully automatic annotation scheme which takes a raw 3D point cloud with a set of fitted CAD models as input, and outputs convincing point-wise labels which can be used as cheap training data for point cloud segmentation. Compared to manual annotations, we show that our automatic labels are accurate while drastically reducing the annotation time, and eliminating the need for manual intervention or dataset-specific parameters. Our labeling pipeline outputs semantic classes and soft point-wise object scores which can either be binarized into standard one-hot-encoded labels, thresholded into weak labels with ambiguous points left unlabeled, or used directly as soft labels during training. We evaluate the label quality and segmentation performance of PointNet++ on a dataset of real industrial point clouds and Scan2CAD, a public dataset of indoor scenes. Our results indicate that reducing supervision in areas which are more difficult to label automatically is beneficial, compared to the conventional approach of naively assigning a hard "best guess" label to every point.
Navigation-Oriented Scene Understanding for Robotic Autonomy: Learning to Segment Driveability in Egocentric Images
Sep 15, 2021
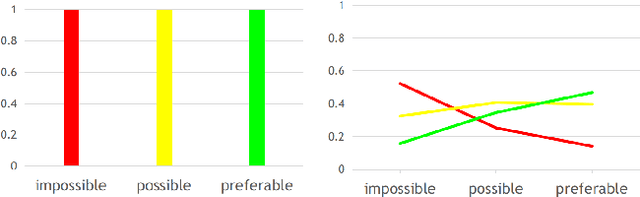


This work tackles scene understanding for outdoor robotic navigation, solely relying on images captured by an on-board camera. Conventional visual scene understanding interprets the environment based on specific descriptive categories. However, such a representation is not directly interpretable for decision-making and constrains robot operation to a specific domain. Thus, we propose to segment egocentric images directly in terms of how a robot can navigate in them, and tailor the learning problem to an autonomous navigation task. Building around an image segmentation network, we present a generic and scalable affordance-based definition consisting of 3 driveability levels which can be applied to arbitrary scenes. By encoding these levels with soft ordinal labels, we incorporate inter-class distances during learning which improves segmentation compared to standard one-hot labelling. In addition, we propose a navigation-oriented pixel-wise loss weighting method which assigns higher importance to safety-critical areas. We evaluate our approach on large-scale public image segmentation datasets spanning off-road and urban scenes. In a zero-shot cross-dataset generalization experiment, we show that our affordance learning scheme can be applied across a diverse mix of datasets and improves driveability estimation in unseen environments compared to general-purpose, single-dataset segmentation.