 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHorse Eye Blink Detection and Classification for Equine Affective State Assessment
Jun 03, 2026Automated detection of equine facial action units (AUs) is a promising yet under-explored avenue for pain and affective state assessment in horses. Half and full-blink movements are recognised indicators of pain and stress, but as micro-expressions, their subtle, fine-grained nature makes them easily missed by the naked eye and only discernible through frame-by-frame video inspection, making reliable automated detection from video a particularly demanding task. We develop and evaluate three methods for automated blink classification from horse videos: a frame-based YOLOv12 detector, an optical flow magnitude thresholding approach, and a fine-tuned VideoMAE model, tested on a publicly available dataset. We achieve a macro-F1 score of 0.898 when doing blink classification and 0.926 on binary blink detection. Our results highlight both the potential and the inherent challenges of fine-grained AU detection for equine welfare monitoring.
Read My Ears! Horse Ear Movement Detection for Equine Affective State Assessment
May 06, 2025The Equine Facial Action Coding System (EquiFACS) enables the systematic annotation of facial movements through distinct Action Units (AUs). It serves as a crucial tool for assessing affective states in horses by identifying subtle facial expressions associated with discomfort. However, the field of horse affective state assessment is constrained by the scarcity of annotated data, as manually labelling facial AUs is both time-consuming and costly. To address this challenge, automated annotation systems are essential for leveraging existing datasets and improving affective states detection tools. In this work, we study different methods for specific ear AU detection and localization from horse videos. We leverage past works on deep learning-based video feature extraction combined with recurrent neural networks for the video classification task, as well as a classic optical flow based approach. We achieve 87.5% classification accuracy of ear movement presence on a public horse video dataset, demonstrating the potential of our approach. We discuss future directions to develop these systems, with the aim of bridging the gap between automated AU detection and practical applications in equine welfare and veterinary diagnostics. Our code will be made publicly available at https://github.com/jmalves5/read-my-ears.
SoccerNet 2022 Challenges Results
Oct 05, 2022



The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team. In 2022, the challenges were composed of 6 vision-based tasks: (1) action spotting, focusing on retrieving action timestamps in long untrimmed videos, (2) replay grounding, focusing on retrieving the live moment of an action shown in a replay, (3) pitch localization, focusing on detecting line and goal part elements, (4) camera calibration, dedicated to retrieving the intrinsic and extrinsic camera parameters, (5) player re-identification, focusing on retrieving the same players across multiple views, and (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams. Compared to last year's challenges, tasks (1-2) had their evaluation metrics redefined to consider tighter temporal accuracies, and tasks (3-6) were novel, including their underlying data and annotations. More information on the tasks, challenges and leaderboards are available on https://www.soccer-net.org. Baselines and development kits are available on https://github.com/SoccerNet.
Navigation-Oriented Scene Understanding for Robotic Autonomy: Learning to Segment Driveability in Egocentric Images
Sep 15, 2021


This work tackles scene understanding for outdoor robotic navigation, solely relying on images captured by an on-board camera. Conventional visual scene understanding interprets the environment based on specific descriptive categories. However, such a representation is not directly interpretable for decision-making and constrains robot operation to a specific domain. Thus, we propose to segment egocentric images directly in terms of how a robot can navigate in them, and tailor the learning problem to an autonomous navigation task. Building around an image segmentation network, we present a generic and scalable affordance-based definition consisting of 3 driveability levels which can be applied to arbitrary scenes. By encoding these levels with soft ordinal labels, we incorporate inter-class distances during learning which improves segmentation compared to standard one-hot labelling. In addition, we propose a navigation-oriented pixel-wise loss weighting method which assigns higher importance to safety-critical areas. We evaluate our approach on large-scale public image segmentation datasets spanning off-road and urban scenes. In a zero-shot cross-dataset generalization experiment, we show that our affordance learning scheme can be applied across a diverse mix of datasets and improves driveability estimation in unseen environments compared to general-purpose, single-dataset segmentation.
Multimodal and multiview distillation for real-time player detection on a football field
Apr 16, 2020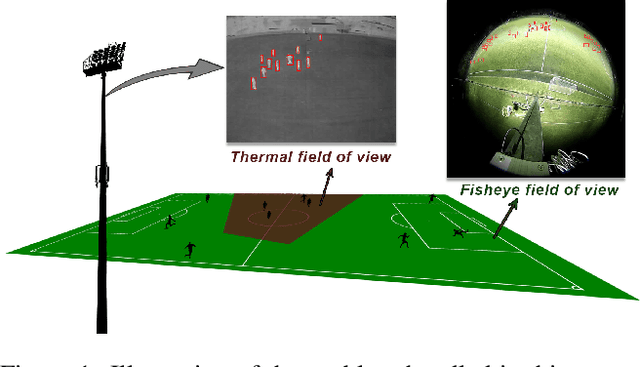



Monitoring the occupancy of public sports facilities is essential to assess their use and to motivate their construction in new places. In the case of a football field, the area to cover is large, thus several regular cameras should be used, which makes the setup expensive and complex. As an alternative, we developed a system that detects players from a unique cheap and wide-angle fisheye camera assisted by a single narrow-angle thermal camera. In this work, we train a network in a knowledge distillation approach in which the student and the teacher have different modalities and a different view of the same scene. In particular, we design a custom data augmentation combined with a motion detection algorithm to handle the training in the region of the fisheye camera not covered by the thermal one. We show that our solution is effective in detecting players on the whole field filmed by the fisheye camera. We evaluate it quantitatively and qualitatively in the case of an online distillation, where the student detects players in real time while being continuously adapted to the latest video conditions.
A Context-Aware Loss Function for Action Spotting in Soccer Videos
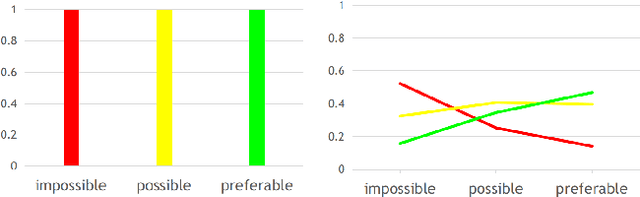
Dec 03, 2019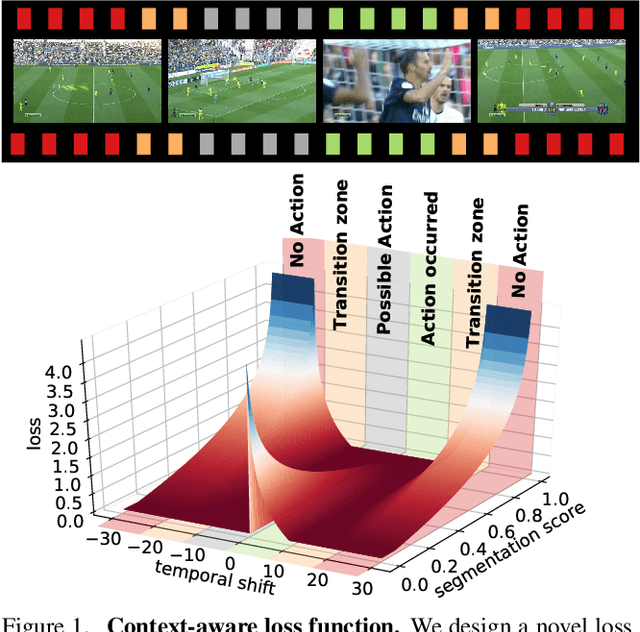
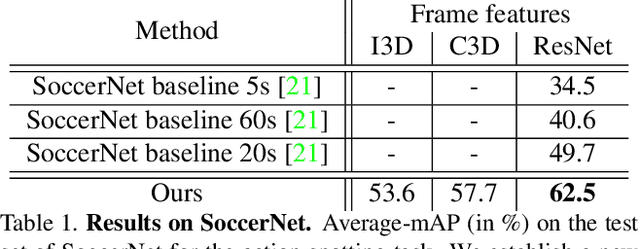
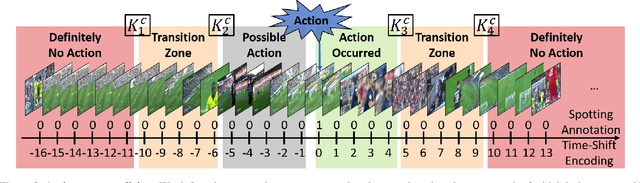
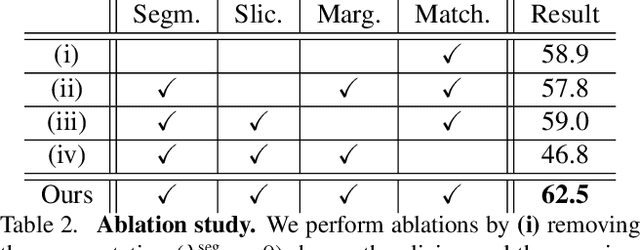
Action spotting is an important element of general activity understanding. It consists of detecting human-induced events annotated with single timestamps. In this paper, we propose a novel loss function for action spotting. Our loss aims at dealing specifically with the temporal context naturally present around an action. Rather than focusing on the single annotated frame of the action to spot, we consider different temporal segments surrounding it and shape our loss function accordingly. We test our loss on SoccerNet, a large dataset of soccer videos, showing an improvement of 12.8% on the current baseline. We also show the generalization capability of our loss function on ActivityNet for activity proposals and detection, by spotting the beginning and the end of each activity. Furthermore, we provide an extended ablation study and identify challenging cases for action spotting in soccer videos. Finally, we qualitatively illustrate how our loss induces a precise temporal understanding of actions, and how such semantic knowledge can be leveraged to design a highlights generator.