 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Context-Aware Loss Function for Action Spotting in Soccer Videos
Paper and Code
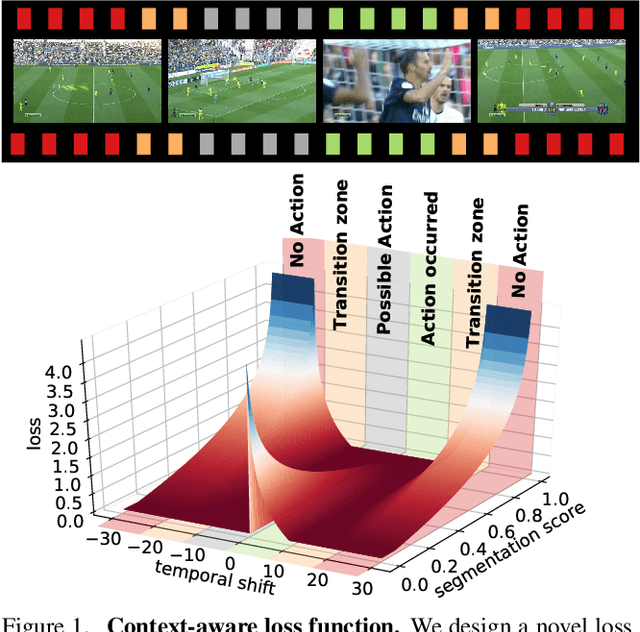
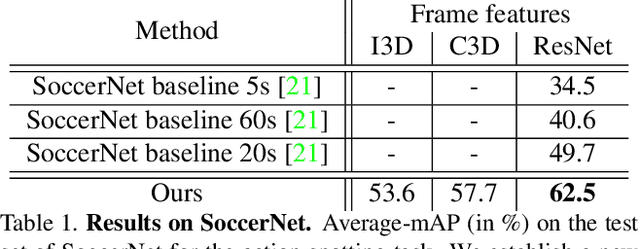
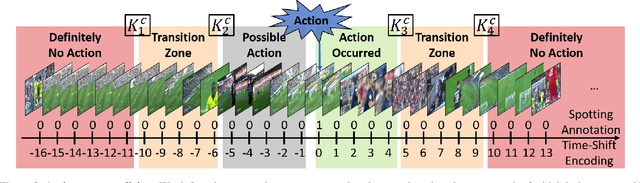
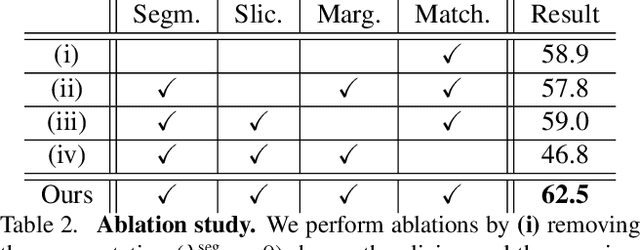
Action spotting is an important element of general activity understanding. It consists of detecting human-induced events annotated with single timestamps. In this paper, we propose a novel loss function for action spotting. Our loss aims at dealing specifically with the temporal context naturally present around an action. Rather than focusing on the single annotated frame of the action to spot, we consider different temporal segments surrounding it and shape our loss function accordingly. We test our loss on SoccerNet, a large dataset of soccer videos, showing an improvement of 12.8% on the current baseline. We also show the generalization capability of our loss function on ActivityNet for activity proposals and detection, by spotting the beginning and the end of each activity. Furthermore, we provide an extended ablation study and identify challenging cases for action spotting in soccer videos. Finally, we qualitatively illustrate how our loss induces a precise temporal understanding of actions, and how such semantic knowledge can be leveraged to design a highlights generator.