 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLRTP2025 Sign Language Production Challenge: Methodology, Results, and Future Work
Aug 09, 2025Sign Language Production (SLP) is the task of generating sign language video from spoken language inputs. The field has seen a range of innovations over the last few years, with the introduction of deep learning-based approaches providing significant improvements in the realism and naturalness of generated outputs. However, the lack of standardized evaluation metrics for SLP approaches hampers meaningful comparisons across different systems. To address this, we introduce the first Sign Language Production Challenge, held as part of the third SLRTP Workshop at CVPR 2025. The competition's aims are to evaluate architectures that translate from spoken language sentences to a sequence of skeleton poses, known as Text-to-Pose (T2P) translation, over a range of metrics. For our evaluation data, we use the RWTH-PHOENIX-Weather-2014T dataset, a German Sign Language - Deutsche Gebardensprache (DGS) weather broadcast dataset. In addition, we curate a custom hidden test set from a similar domain of discourse. This paper presents the challenge design and the winning methodologies. The challenge attracted 33 participants who submitted 231 solutions, with the top-performing team achieving BLEU-1 scores of 31.40 and DTW-MJE of 0.0574. The winning approach utilized a retrieval-based framework and a pre-trained language model. As part of the workshop, we release a standardized evaluation network, including high-quality skeleton extraction-based keypoints establishing a consistent baseline for the SLP field, which will enable future researchers to compare their work against a broader range of methods.
Hierarchical Feature Alignment for Gloss-Free Sign Language Translation
Jul 09, 2025Sign Language Translation (SLT) attempts to convert sign language videos into spoken sentences. However, many existing methods struggle with the disparity between visual and textual representations during end-to-end learning. Gloss-based approaches help to bridge this gap by leveraging structured linguistic information. While, gloss-free methods offer greater flexibility and remove the burden of annotation, they require effective alignment strategies. Recent advances in Large Language Models (LLMs) have enabled gloss-free SLT by generating text-like representations from sign videos. In this work, we introduce a novel hierarchical pre-training strategy inspired by the structure of sign language, incorporating pseudo-glosses and contrastive video-language alignment. Our method hierarchically extracts features at frame, segment, and video levels, aligning them with pseudo-glosses and the spoken sentence to enhance translation quality. Experiments demonstrate that our approach improves BLEU-4 and ROUGE scores while maintaining efficiency.
Diversity-Aware Sign Language Production through a Pose Encoding Variational Autoencoder
May 16, 2024This paper addresses the problem of diversity-aware sign language production, where we want to give an image (or sequence) of a signer and produce another image with the same pose but different attributes (\textit{e.g.} gender, skin color). To this end, we extend the variational inference paradigm to include information about the pose and the conditioning of the attributes. This formulation improves the quality of the synthesised images. The generator framework is presented as a UNet architecture to ensure spatial preservation of the input pose, and we include the visual features from the variational inference to maintain control over appearance and style. We generate each body part with a separate decoder. This architecture allows the generator to deliver better overall results. Experiments on the SMILE II dataset show that the proposed model performs quantitatively better than state-of-the-art baselines regarding diversity, per-pixel image quality, and pose estimation. Quantitatively, it faithfully reproduces non-manual features for signers.
Novel-View Human Action Synthesis
Jul 06, 2020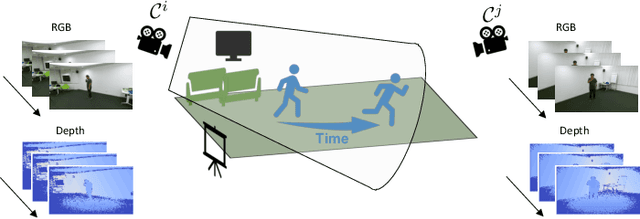

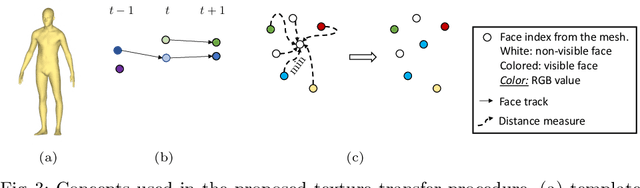

Novel-View Human Action Synthesis aims to synthesize the appearance of a dynamic scene from a virtual viewpoint, given a video from a real viewpoint. Our approach uses a novel 3D reasoning to synthesize the target viewpoint. We first estimate the 3D mesh of the target object, a human actor, and transfer the rough textures from the 2D images to the mesh. This transfer may generate sparse textures on the mesh due to frame resolution or occlusions. To solve this problem, we produce a semi-dense textured mesh by propagating the transferred textures both locally, within local geodesic neighborhoods, and globally, across symmetric semantic parts. Next, we introduce a context-based generator to learn how to correct and complete the residual appearance information. This allows the network to independently focus of learning the foreground and background synthesis tasks. We validate the proposed solution on the public NTU RGB+D dataset. The code and resources are available at \url{https://mlakhal.github.io/novel-view_action_synthesis/}.