 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovel-View Human Action Synthesis
Paper and Code
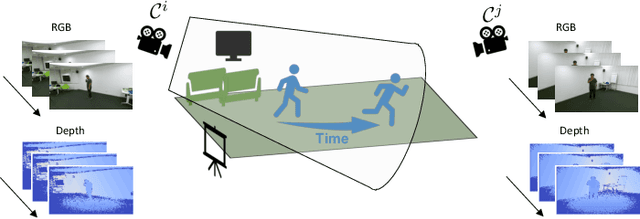

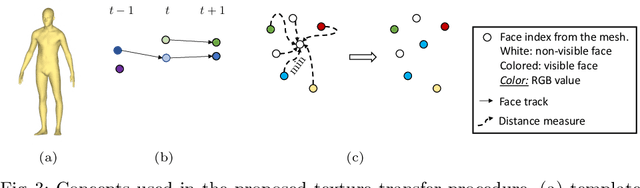

Novel-View Human Action Synthesis aims to synthesize the appearance of a dynamic scene from a virtual viewpoint, given a video from a real viewpoint. Our approach uses a novel 3D reasoning to synthesize the target viewpoint. We first estimate the 3D mesh of the target object, a human actor, and transfer the rough textures from the 2D images to the mesh. This transfer may generate sparse textures on the mesh due to frame resolution or occlusions. To solve this problem, we produce a semi-dense textured mesh by propagating the transferred textures both locally, within local geodesic neighborhoods, and globally, across symmetric semantic parts. Next, we introduce a context-based generator to learn how to correct and complete the residual appearance information. This allows the network to independently focus of learning the foreground and background synthesis tasks. We validate the proposed solution on the public NTU RGB+D dataset. The code and resources are available at \url{https://mlakhal.github.io/novel-view_action_synthesis/}.