 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaskFuser: Masked Fusion of Joint Multi-Modal Tokenization for End-to-End Autonomous Driving
Paper and Code
May 13, 2024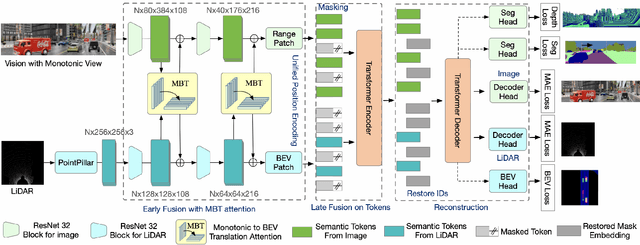

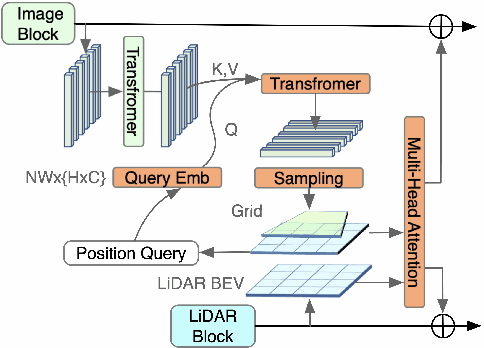
Current multi-modality driving frameworks normally fuse representation by utilizing attention between single-modality branches. However, the existing networks still suppress the driving performance as the Image and LiDAR branches are independent and lack a unified observation representation. Thus, this paper proposes MaskFuser, which tokenizes various modalities into a unified semantic feature space and provides a joint representation for further behavior cloning in driving contexts. Given the unified token representation, MaskFuser is the first work to introduce cross-modality masked auto-encoder training. The masked training enhances the fusion representation by reconstruction on masked tokens. Architecturally, a hybrid-fusion network is proposed to combine advantages from both early and late fusion: For the early fusion stage, modalities are fused by performing monotonic-to-BEV translation attention between branches; Late fusion is performed by tokenizing various modalities into a unified token space with shared encoding on it. MaskFuser respectively reaches a driving score of 49.05 and route completion of 92.85% on the CARLA LongSet6 benchmark evaluation, which improves the best of previous baselines by 1.74 and 3.21%. The introduced masked fusion increases driving stability under damaged sensory inputs. MaskFuser outperforms the best of previous baselines on driving score by 6.55 (27.8%), 1.53 (13.8%), 1.57 (30.9%), respectively given sensory masking ratios 25%, 50%, and 75%.