 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimultaneous Machine Translation with Large Language Models
Paper and Code
Sep 13, 2023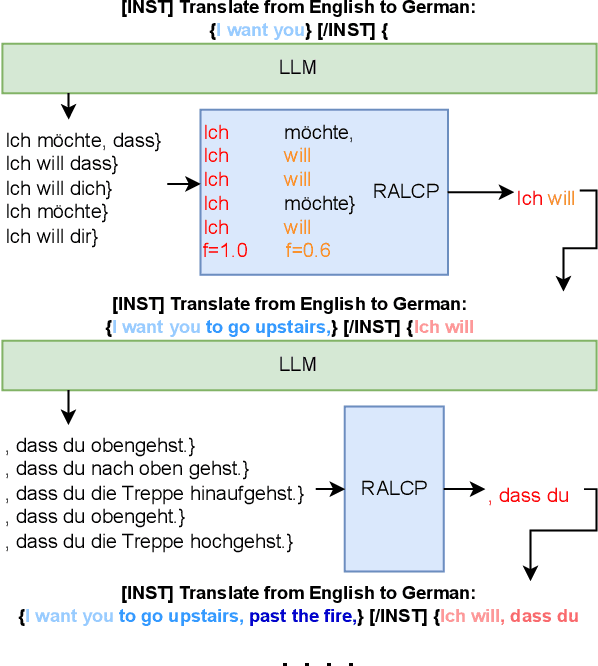


Large language models (LLM) have demonstrated their abilities to solve various natural language processing tasks through dialogue-based interactions. For instance, research indicates that LLMs can achieve competitive performance in offline machine translation tasks for high-resource languages. However, applying LLMs to simultaneous machine translation (SimulMT) poses many challenges, including issues related to the training-inference mismatch arising from different decoding patterns. In this paper, we explore the feasibility of utilizing LLMs for SimulMT. Building upon conventional approaches, we introduce a simple yet effective mixture policy that enables LLMs to engage in SimulMT without requiring additional training. Furthermore, after Supervised Fine-Tuning (SFT) on a mixture of full and prefix sentences, the model exhibits significant performance improvements. Our experiments, conducted with Llama2-7B-chat on nine language pairs from the MUST-C dataset, demonstrate that LLM can achieve translation quality and latency comparable to dedicated SimulMT models.