 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Unnatural Questions Improves Reasoning over Text
Paper and Code
Oct 19, 2020

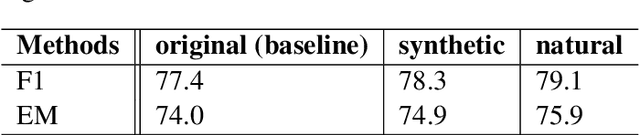
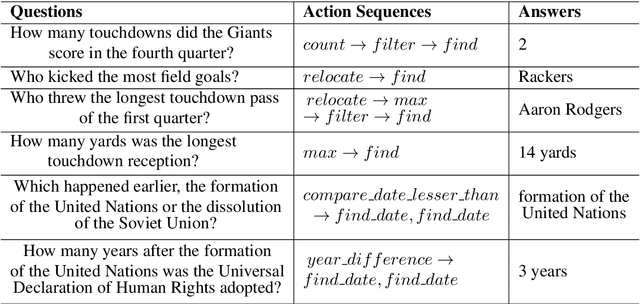
Complex question answering (CQA) over raw text is a challenging task. A prominent approach to this task is based on the programmer-interpreter framework, where the programmer maps the question into a sequence of reasoning actions which is then executed on the raw text by the interpreter. Learning an effective CQA model requires large amounts of human-annotated data,consisting of the ground-truth sequence of reasoning actions, which is time-consuming and expensive to collect at scale. In this paper, we address the challenge of learning a high-quality programmer (parser) by projecting natural human-generated questions into unnatural machine-generated questions which are more convenient to parse. We firstly generate synthetic (question,action sequence) pairs by a data generator, and train a semantic parser that associates synthetic questions with their corresponding action sequences. To capture the diversity when applied tonatural questions, we learn a projection model to map natural questions into their most similar unnatural questions for which the parser can work well. Without any natural training data, our projection model provides high-quality action sequences for the CQA task. Experimental results show that the QA model trained exclusively with synthetic data generated by our method outperforms its state-of-the-art counterpart trained on human-labeled data.