 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Robustness of (Graph) Neural Networks Against Data Poisoning and Backdoor Attacks
Paper and Code
Jul 15, 2024
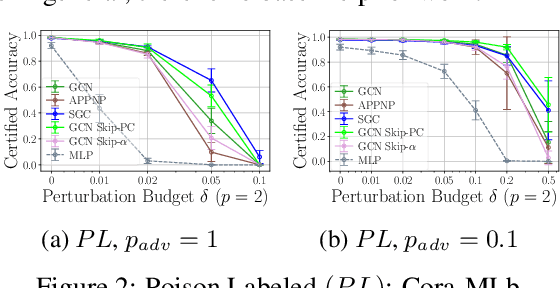
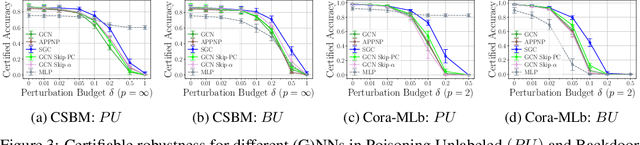
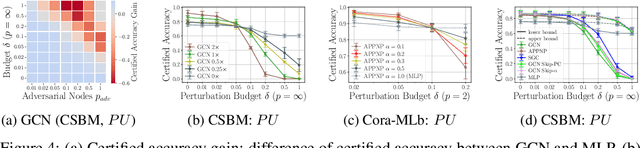
Generalization of machine learning models can be severely compromised by data poisoning, where adversarial changes are applied to the training data, as well as backdoor attacks that additionally manipulate the test data. These vulnerabilities have led to interest in certifying (i.e., proving) that such changes up to a certain magnitude do not affect test predictions. We, for the first time, certify Graph Neural Networks (GNNs) against poisoning and backdoor attacks targeting the node features of a given graph. Our certificates are white-box and based upon $(i)$ the neural tangent kernel, which characterizes the training dynamics of sufficiently wide networks; and $(ii)$ a novel reformulation of the bilevel optimization problem describing poisoning as a mixed-integer linear program. Consequently, we leverage our framework to provide fundamental insights into the role of graph structure and its connectivity on the worst-case robustness behavior of convolution-based and PageRank-based GNNs. We note that our framework is more general and constitutes the first approach to derive white-box poisoning certificates for NNs, which can be of independent interest beyond graph-related tasks.