 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Borders: Investigating Cross-Jurisdiction Transfer in Legal Case Summarization
Paper and Code
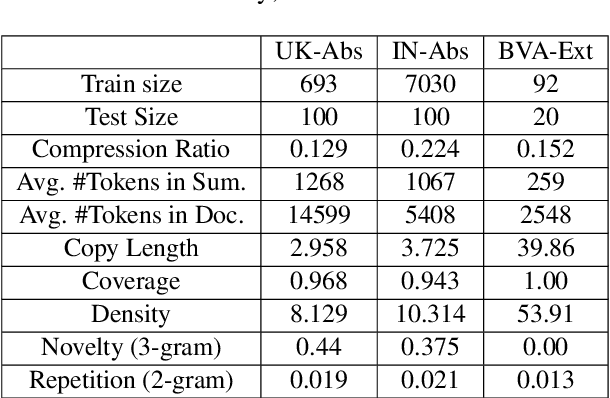
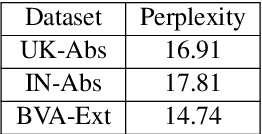
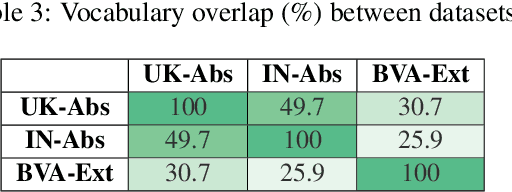
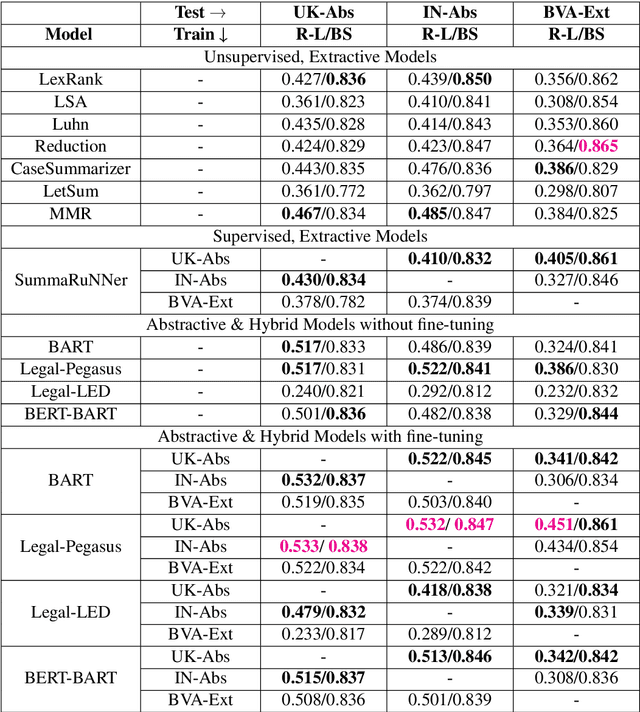
Legal professionals face the challenge of managing an overwhelming volume of lengthy judgments, making automated legal case summarization crucial. However, prior approaches mainly focused on training and evaluating these models within the same jurisdiction. In this study, we explore the cross-jurisdictional generalizability of legal case summarization models.Specifically, we explore how to effectively summarize legal cases of a target jurisdiction where reference summaries are not available. In particular, we investigate whether supplementing models with unlabeled target jurisdiction corpus and extractive silver summaries obtained from unsupervised algorithms on target data enhances transfer performance. Our comprehensive study on three datasets from different jurisdictions highlights the role of pre-training in improving transfer performance. We shed light on the pivotal influence of jurisdictional similarity in selecting optimal source datasets for effective transfer. Furthermore, our findings underscore that incorporating unlabeled target data yields improvements in general pre-trained models, with additional gains when silver summaries are introduced. This augmentation is especially valuable when dealing with extractive datasets and scenarios featuring limited alignment between source and target jurisdictions. Our study provides key insights for developing adaptable legal case summarization systems, transcending jurisdictional boundaries.