 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Auditor: Interactive Visualization for Detection and Summarization of Model Biases
Jun 25, 2022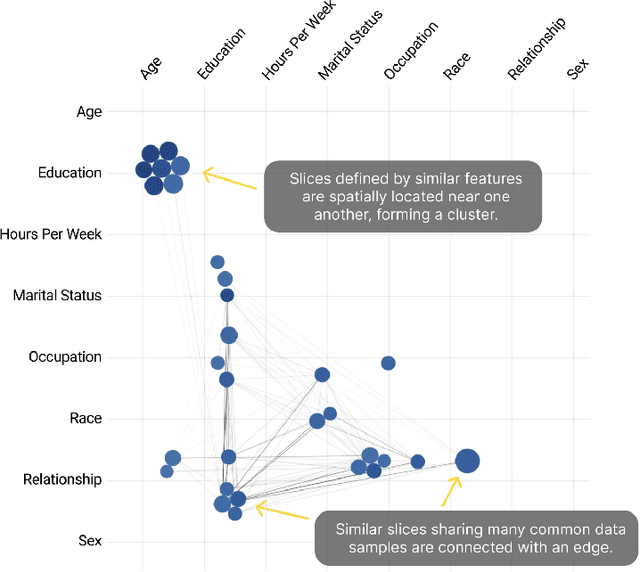

As machine learning (ML) systems become increasingly widespread, it is necessary to audit these systems for biases prior to their deployment. Recent research has developed algorithms for effectively identifying intersectional bias in the form of interpretable, underperforming subsets (or slices) of the data. However, these solutions and their insights are limited without a tool for visually understanding and interacting with the results of these algorithms. We propose Visual Auditor, an interactive visualization tool for auditing and summarizing model biases. Visual Auditor assists model validation by providing an interpretable overview of intersectional bias (bias that is present when examining populations defined by multiple features), details about relationships between problematic data slices, and a comparison between underperforming and overperforming data slices in a model. Our open-source tool runs directly in both computational notebooks and web browsers, making model auditing accessible and easily integrated into current ML development workflows. An observational user study in collaboration with domain experts at Fiddler AI highlights that our tool can help ML practitioners identify and understand model biases.
Unified Shapley Framework to Explain Prediction Drift
Feb 15, 2021



Predictions are the currency of a machine learning model, and to understand the model's behavior over segments of a dataset, or over time, is an important problem in machine learning research and practice. There currently is no systematic framework to understand this drift in prediction distributions over time or between two semantically meaningful slices of data, in terms of the input features and points. We propose GroupShapley and GroupIG (Integrated Gradients), as axiomatically justified methods to tackle this problem. In doing so, we re-frame all current feature/data importance measures based on the Shapley value as essentially problems of distributional comparisons, and unify them under a common umbrella. We axiomatize certain desirable properties of distributional difference, and study the implications of choosing them empirically.