 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairCanary: Rapid Continuous Explainable Fairness
Jun 13, 2021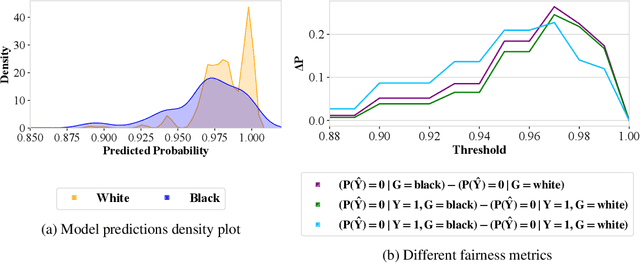
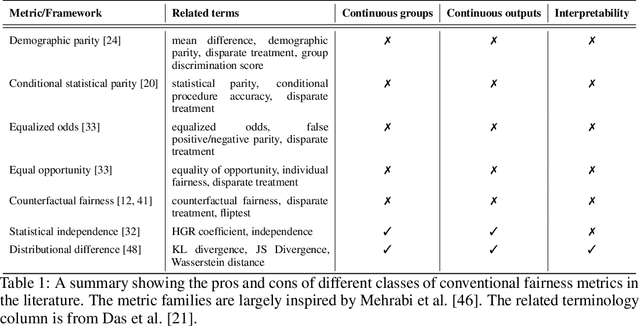
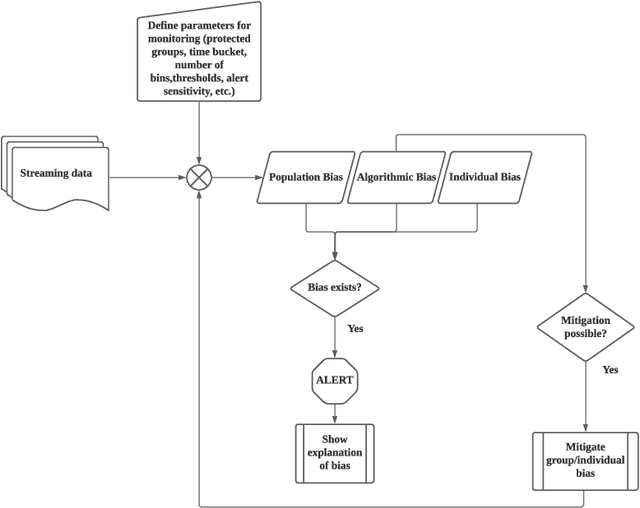
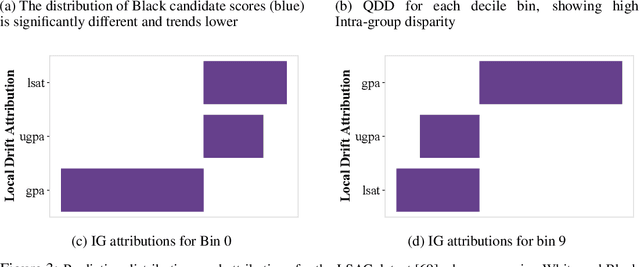
Machine Learning (ML) models are being used in all facets of today's society to make high stake decisions like bail granting or credit lending, with very minimal regulations. Such systems are extremely vulnerable to both propagating and amplifying social biases, and have therefore been subject to growing research interest. One of the main issues with conventional fairness metrics is their narrow definitions which hide the complete extent of the bias by focusing primarily on positive and/or negative outcomes, whilst not paying attention to the overall distributional shape. Moreover, these metrics are often contradictory to each other, are severely restrained by the contextual and legal landscape of the problem, have technical constraints like poor support for continuous outputs, the requirement of class labels, and are not explainable. In this paper, we present Quantile Demographic Drift, which addresses the shortcomings mentioned above. This metric can also be used to measure intra-group privilege. It is easily interpretable via existing attribution techniques, and also extends naturally to individual fairness via the principle of like-for-like comparison. We make this new fairness score the basis of a new system that is designed to detect bias in production ML models without the need for labels. We call the system FairCanary because of its capability to detect bias in a live deployed model and narrow down the alert to the responsible set of features, like the proverbial canary in a coal mine.
Unified Shapley Framework to Explain Prediction Drift
Feb 15, 2021



Predictions are the currency of a machine learning model, and to understand the model's behavior over segments of a dataset, or over time, is an important problem in machine learning research and practice. There currently is no systematic framework to understand this drift in prediction distributions over time or between two semantically meaningful slices of data, in terms of the input features and points. We propose GroupShapley and GroupIG (Integrated Gradients), as axiomatically justified methods to tackle this problem. In doing so, we re-frame all current feature/data importance measures based on the Shapley value as essentially problems of distributional comparisons, and unify them under a common umbrella. We axiomatize certain desirable properties of distributional difference, and study the implications of choosing them empirically.