 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Resource Vision Challenges for Foundation Models
Jan 10, 2024Low-resource settings are well-established in natural language processing, where many languages lack sufficient data for machine learning at scale. However, low-resource problems are under-explored in computer vision. In this paper, we strive to address this gap and explore the challenges of low-resource image tasks with vision foundation models. Thus, we first collect a benchmark of genuinely low-resource image data, covering historic maps, circuit diagrams, and mechanical drawings. These low-resource settings all share the three challenges of data scarcity, fine-grained differences, and the distribution shift from natural images to the specialized domain of interest. While existing foundation models have shown impressive generalizability, we find they cannot transfer well to our low-resource tasks. To begin to tackle the challenges of low-resource vision, we introduce one simple baseline per challenge. Specifically, we propose to i) enlarge the data space by generative models, ii) adopt the best sub-kernels to encode local regions for fine-grained difference discovery and iii) learn attention for specialized domains. Experiments on the three low-resource data sources in our benchmark demonstrate our proposals already provide a better baseline than common transfer learning, data augmentation, and fine-grained methods. This highlights the unique characteristics and challenges of low-resource vision for foundation models that warrant further investigation. Project website: https://xiaobai1217.github.io/Low-Resource-Vision/.
Learning Unseen Modality Interaction
Jun 22, 2023Multimodal learning assumes all modality combinations of interest are available during training to learn cross-modal correspondences. In this paper, we challenge this modality-complete assumption for multimodal learning and instead strive for generalization to unseen modality combinations during inference. We pose the problem of unseen modality interaction and introduce a first solution. It exploits a feature projection module to project the multidimensional features of different modalities into a common space with rich information reserved. This allows the information to be accumulated with a simple summation operation across available modalities. To reduce overfitting to unreliable modality combinations during training, we further improve the model learning with pseudo-supervision indicating the reliability of a modality's prediction. We demonstrate that our approach is effective for diverse tasks and modalities by evaluating it for multimodal video classification, robot state regression, and multimedia retrieval.
Day2Dark: Pseudo-Supervised Activity Recognition beyond Silent Daylight
Dec 05, 2022State-of-the-art activity recognizers are effective during the day, but not trustworthy in the dark. The main causes are the distribution shift from the lower color contrast as well as the limited availability of labeled dark videos. Our goal is to recognize activities in the dark as well as in the day. To compensate for the lack of labeled dark videos, we introduce a pseudo-supervised learning scheme, which utilizes task-irrelevant unlabeled dark videos to train an activity recognizer. Our proposed activity recognizer makes use of audio which is invariant to illumination. However, the usefulness of audio and visual features differs according to the illumination. Thus we propose to make our audio-visual recognizer `darkness-aware'. Experiments on EPIC-Kitchens, Kinetics-Sound, and Charades demonstrate that our proposals enable effective activity recognition in the dark and can even improve robustness to occlusions.
TANet: Transformer-based Asymmetric Network for RGB-D Salient Object Detection
Jul 04, 2022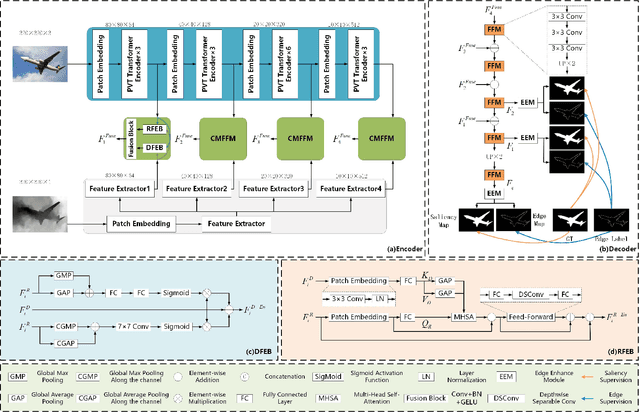

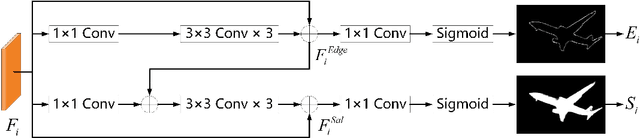

Existing RGB-D SOD methods mainly rely on a symmetric two-stream CNN-based network to extract RGB and depth channel features separately. However, there are two problems with the symmetric conventional network structure: first, the ability of CNN in learning global contexts is limited; second, the symmetric two-stream structure ignores the inherent differences between modalities. In this paper, we propose a Transformer-based asymmetric network (TANet) to tackle the issues mentioned above. We employ the powerful feature extraction capability of Transformer (PVTv2) to extract global semantic information from RGB data and design a lightweight CNN backbone (LWDepthNet) to extract spatial structure information from depth data without pre-training. The asymmetric hybrid encoder (AHE) effectively reduces the number of parameters in the model while increasing speed without sacrificing performance. Then, we design a cross-modal feature fusion module (CMFFM), which enhances and fuses RGB and depth features with each other. Finally, we add edge prediction as an auxiliary task and propose an edge enhancement module (EEM) to generate sharper contours. Extensive experiments demonstrate that our method achieves superior performance over 14 state-of-the-art RGB-D methods on six public datasets. Our code will be released at https://github.com/lc012463/TANet.
Audio-Adaptive Activity Recognition Across Video Domains
Mar 29, 2022

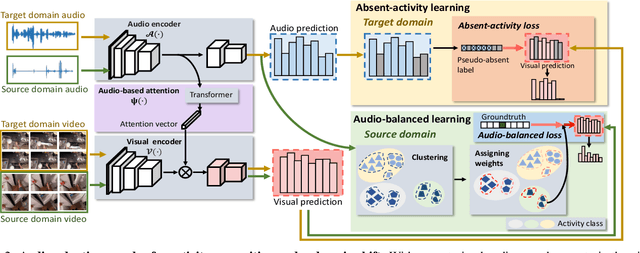
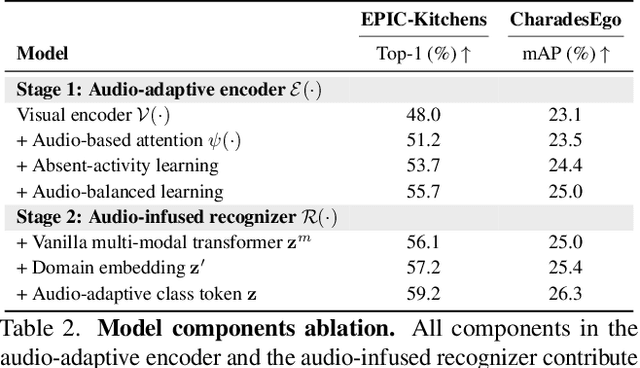
This paper strives for activity recognition under domain shift, for example caused by change of scenery or camera viewpoint. The leading approaches reduce the shift in activity appearance by adversarial training and self-supervised learning. Different from these vision-focused works we leverage activity sounds for domain adaptation as they have less variance across domains and can reliably indicate which activities are not happening. We propose an audio-adaptive encoder and associated learning methods that discriminatively adjust the visual feature representation as well as addressing shifts in the semantic distribution. To further eliminate domain-specific features and include domain-invariant activity sounds for recognition, an audio-infused recognizer is proposed, which effectively models the cross-modal interaction across domains. We also introduce the new task of actor shift, with a corresponding audio-visual dataset, to challenge our method with situations where the activity appearance changes dramatically. Experiments on this dataset, EPIC-Kitchens and CharadesEgo show the effectiveness of our approach.
Repetitive Activity Counting by Sight and Sound
Apr 17, 2021
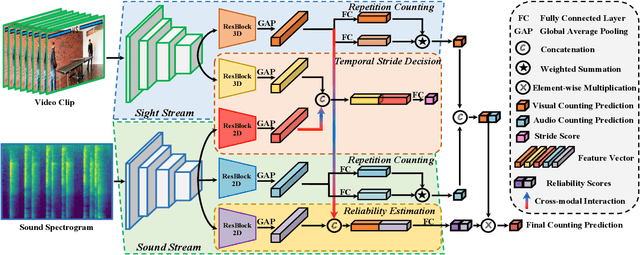
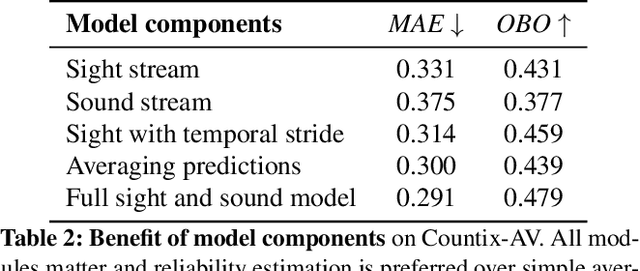
This paper strives for repetitive activity counting in videos. Different from existing works, which all analyze the visual video content only, we incorporate for the first time the corresponding sound into the repetition counting process. This benefits accuracy in challenging vision conditions such as occlusion, dramatic camera view changes, low resolution, etc. We propose a model that starts with analyzing the sight and sound streams separately. Then an audiovisual temporal stride decision module and a reliability estimation module are introduced to exploit cross-modal temporal interaction. For learning and evaluation, an existing dataset is repurposed and reorganized to allow for repetition counting with sight and sound. We also introduce a variant of this dataset for repetition counting under challenging vision conditions. Experiments demonstrate the benefit of sound, as well as the other introduced modules, for repetition counting. Our sight-only model already outperforms the state-of-the-art by itself, when we add sound, results improve notably, especially under harsh vision conditions.
High-Performance Long-Term Tracking with Meta-Updater
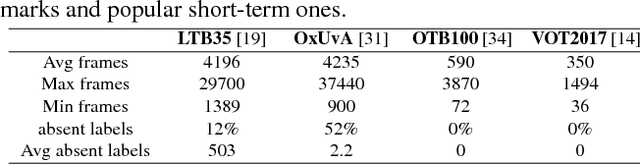
Apr 01, 2020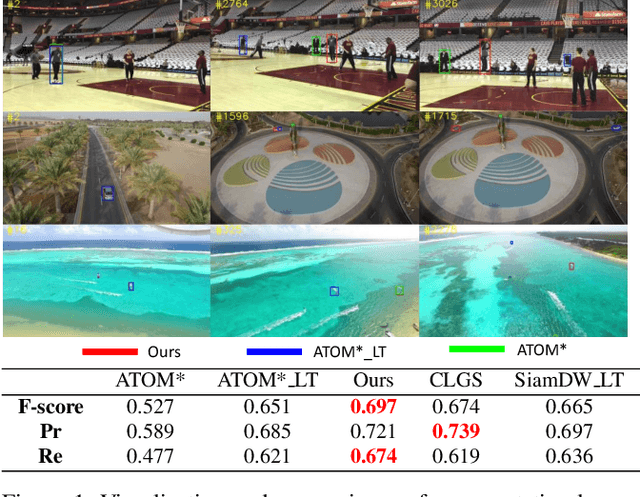

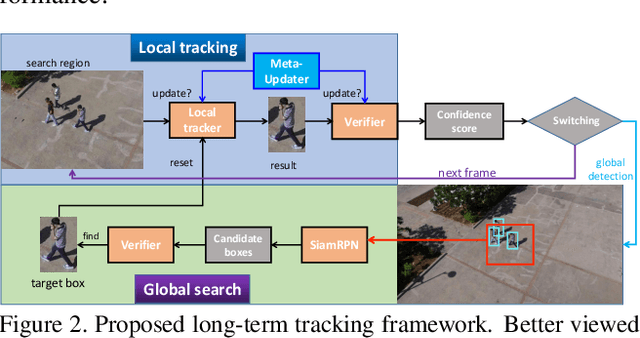
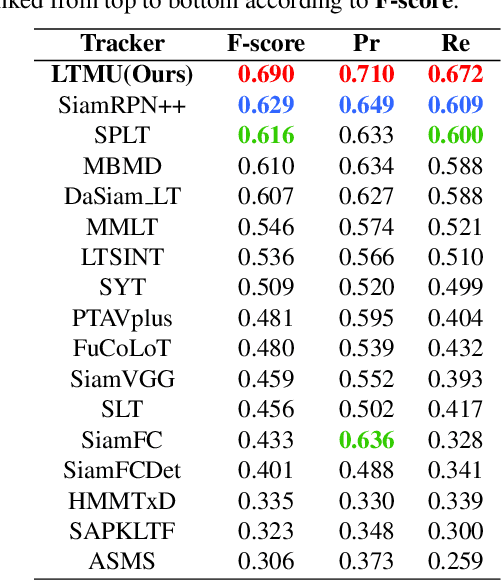
Long-term visual tracking has drawn increasing attention because it is much closer to practical applications than short-term tracking. Most top-ranked long-term trackers adopt the offline-trained Siamese architectures, thus, they cannot benefit from great progress of short-term trackers with online update. However, it is quite risky to straightforwardly introduce online-update-based trackers to solve the long-term problem, due to long-term uncertain and noisy observations. In this work, we propose a novel offline-trained Meta-Updater to address an important but unsolved problem: Is the tracker ready for updating in the current frame? The proposed meta-updater can effectively integrate geometric, discriminative, and appearance cues in a sequential manner, and then mine the sequential information with a designed cascaded LSTM module. Our meta-updater learns a binary output to guide the tracker's update and can be easily embedded into different trackers. This work also introduces a long-term tracking framework consisting of an online local tracker, an online verifier, a SiamRPN-based re-detector, and our meta-updater. Numerous experimental results on the VOT2018LT, VOT2019LT, OxUvALT, TLP, and LaSOT benchmarks show that our tracker performs remarkably better than other competing algorithms. Our project is available on the website: https://github.com/Daikenan/LTMU.
Learning regression and verification networks for long-term visual tracking
Sep 12, 2018
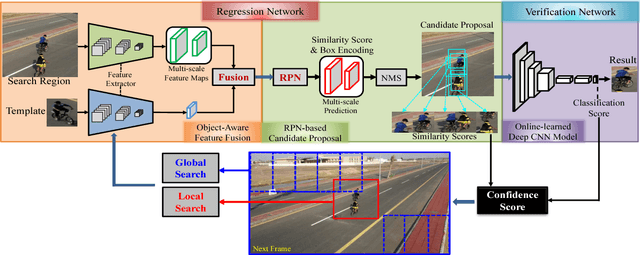
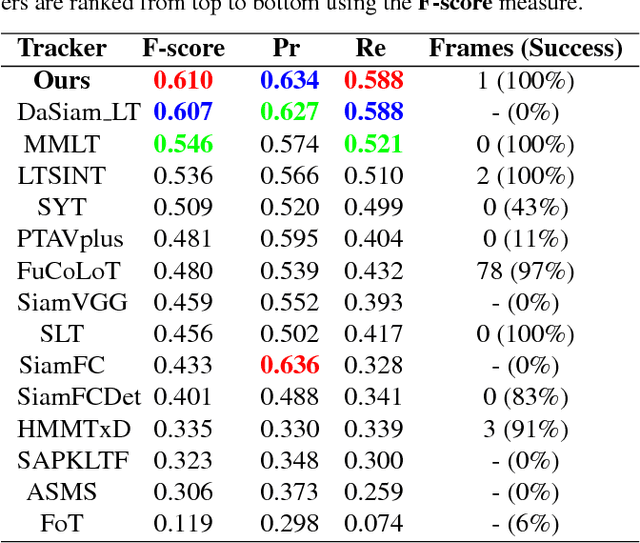
In the long-term single object tracking task, the target moves out of view frequently. It is difficult to determine the presence of the target and re-search the target in the entire image. In this paper, we circumvent this issue by introducing a collaborative framework that exploits both matching mechanism and discriminative features to account for target identification and image-wide re-detection. Within the proposed collaborative framework, we develop a matching based regression module and a classification based verification module for long-term visual tracking. In the regression module, we present a regressor that conducts matching learning and copes with drastic appearance changes. In the verification module, we propose a classifier that filters out distractions efficiently. Compared to previous long-term trackers, the proposed tracker is able to track the target object more robustly in long-term sequences. Extensive experiments show that our algorithm achieves state-of-the-art results on several datasets.