 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTANet: Transformer-based Asymmetric Network for RGB-D Salient Object Detection
Paper and Code
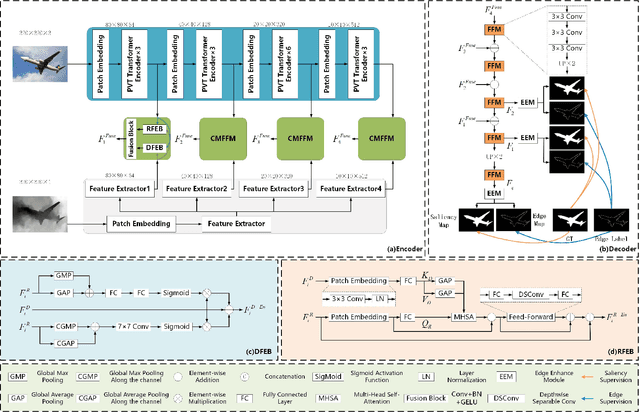

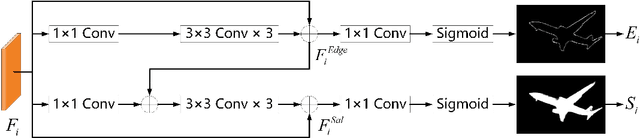

Existing RGB-D SOD methods mainly rely on a symmetric two-stream CNN-based network to extract RGB and depth channel features separately. However, there are two problems with the symmetric conventional network structure: first, the ability of CNN in learning global contexts is limited; second, the symmetric two-stream structure ignores the inherent differences between modalities. In this paper, we propose a Transformer-based asymmetric network (TANet) to tackle the issues mentioned above. We employ the powerful feature extraction capability of Transformer (PVTv2) to extract global semantic information from RGB data and design a lightweight CNN backbone (LWDepthNet) to extract spatial structure information from depth data without pre-training. The asymmetric hybrid encoder (AHE) effectively reduces the number of parameters in the model while increasing speed without sacrificing performance. Then, we design a cross-modal feature fusion module (CMFFM), which enhances and fuses RGB and depth features with each other. Finally, we add edge prediction as an auxiliary task and propose an edge enhancement module (EEM) to generate sharper contours. Extensive experiments demonstrate that our method achieves superior performance over 14 state-of-the-art RGB-D methods on six public datasets. Our code will be released at https://github.com/lc012463/TANet.