 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Modeling Uncertain Feature Representation for Domain Generalization
Jan 16, 2023Though deep neural networks have achieved impressive success on various vision tasks, obvious performance degradation still exists when models are tested in out-of-distribution scenarios. In addressing this limitation, we ponder that the feature statistics (mean and standard deviation), which carry the domain characteristics of the training data, can be properly manipulated to improve the generalization ability of deep learning models. Existing methods commonly consider feature statistics as deterministic values measured from the learned features and do not explicitly model the uncertain statistics discrepancy caused by potential domain shifts during testing. In this paper, we improve the network generalization ability by modeling domain shifts with uncertainty (DSU), i.e., characterizing the feature statistics as uncertain distributions during training. Specifically, we hypothesize that the feature statistic, after considering the potential uncertainties, follows a multivariate Gaussian distribution. During inference, we propose an instance-wise adaptation strategy that can adaptively deal with the unforeseeable shift and further enhance the generalization ability of the trained model with negligible additional cost. We also conduct theoretical analysis on the aspects of generalization error bound and the implicit regularization effect, showing the efficacy of our method. Extensive experiments demonstrate that our method consistently improves the network generalization ability on multiple vision tasks, including image classification, semantic segmentation, instance retrieval, and pose estimation. Our methods are simple yet effective and can be readily integrated into networks without additional trainable parameters or loss constraints. Code will be released in https://github.com/lixiaotong97/DSU.
Bridging the Source-to-target Gap for Cross-domain Person Re-Identification with Intermediate Domains
Mar 03, 2022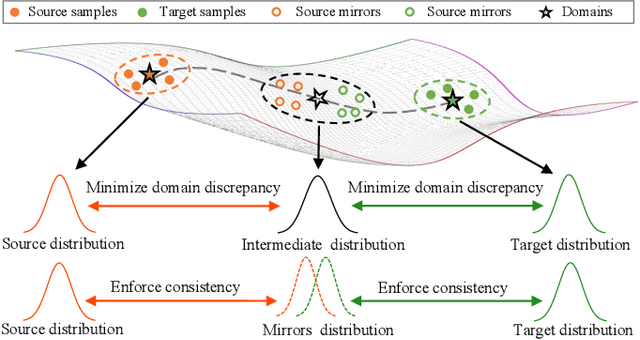
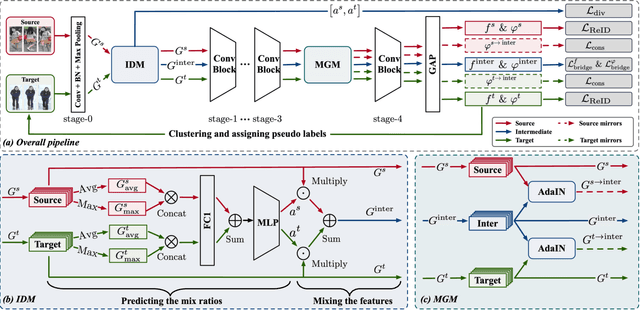
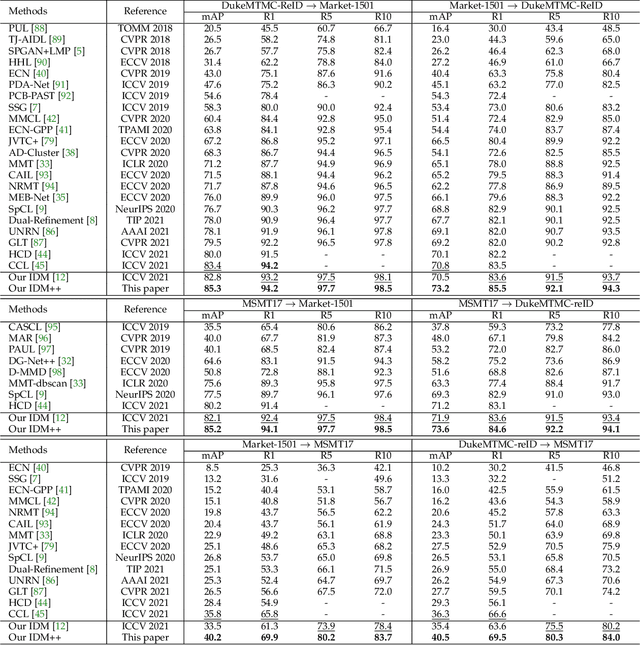
Cross-domain person re-identification (re-ID), such as unsupervised domain adaptive (UDA) re-ID, aims to transfer the identity-discriminative knowledge from the source to the target domain. Existing methods commonly consider the source and target domains are isolated from each other, i.e., no intermediate status is modeled between both domains. Directly transferring the knowledge between two isolated domains can be very difficult, especially when the domain gap is large. From a novel perspective, we assume these two domains are not completely isolated, but can be connected through intermediate domains. Instead of directly aligning the source and target domains against each other, we propose to align the source and target domains against their intermediate domains for a smooth knowledge transfer. To discover and utilize these intermediate domains, we propose an Intermediate Domain Module (IDM) and a Mirrors Generation Module (MGM). IDM has two functions: 1) it generates multiple intermediate domains by mixing the hidden-layer features from source and target domains and 2) it dynamically reduces the domain gap between the source / target domain features and the intermediate domain features. While IDM achieves good domain alignment, it introduces a side effect, i.e., the mix-up operation may mix the identities into a new identity and lose the original identities. To compensate this, MGM is introduced by mapping the features into the IDM-generated intermediate domains without changing their original identity. It allows to focus on minimizing domain variations to promote the alignment between the source / target domain and intermediate domains, which reinforces IDM into IDM++. We extensively evaluate our method under both the UDA and domain generalization (DG) scenarios and observe that IDM++ yields consistent performance improvement for cross-domain re-ID, achieving new state of the art.
Uncertainty Modeling for Out-of-Distribution Generalization
Feb 08, 2022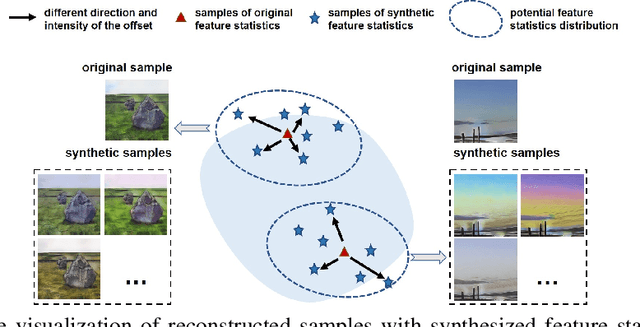
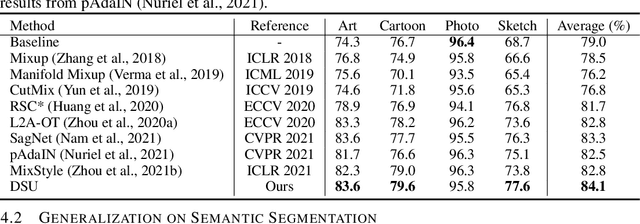
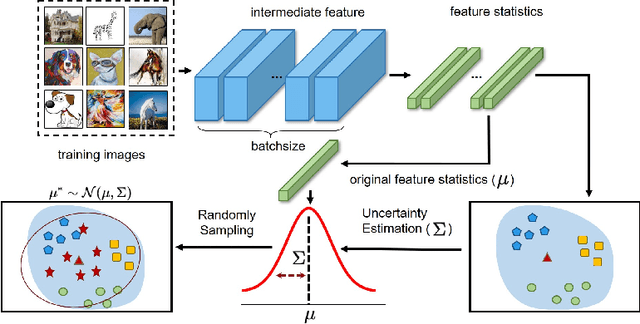

Though remarkable progress has been achieved in various vision tasks, deep neural networks still suffer obvious performance degradation when tested in out-of-distribution scenarios. We argue that the feature statistics (mean and standard deviation), which carry the domain characteristics of the training data, can be properly manipulated to improve the generalization ability of deep learning models. Common methods often consider the feature statistics as deterministic values measured from the learned features and do not explicitly consider the uncertain statistics discrepancy caused by potential domain shifts during testing. In this paper, we improve the network generalization ability by modeling the uncertainty of domain shifts with synthesized feature statistics during training. Specifically, we hypothesize that the feature statistic, after considering the potential uncertainties, follows a multivariate Gaussian distribution. Hence, each feature statistic is no longer a deterministic value, but a probabilistic point with diverse distribution possibilities. With the uncertain feature statistics, the models can be trained to alleviate the domain perturbations and achieve better robustness against potential domain shifts. Our method can be readily integrated into networks without additional parameters. Extensive experiments demonstrate that our proposed method consistently improves the network generalization ability on multiple vision tasks, including image classification, semantic segmentation, and instance retrieval. The code will be released soon at https://github.com/lixiaotong97/DSU.
IDM: An Intermediate Domain Module for Domain Adaptive Person Re-ID
Aug 05, 2021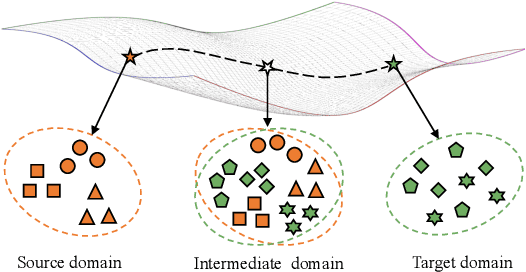
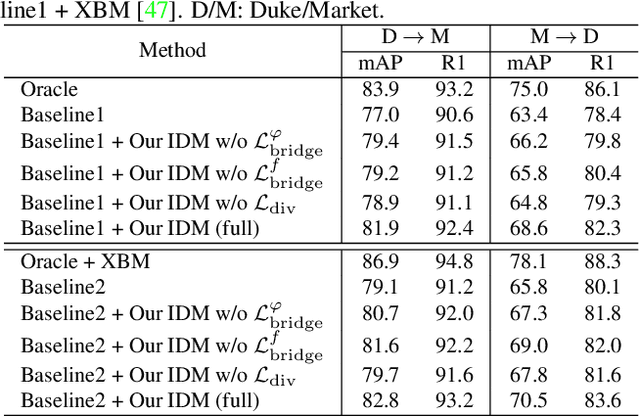
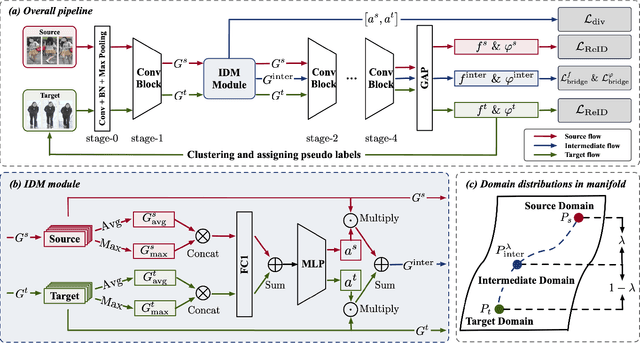
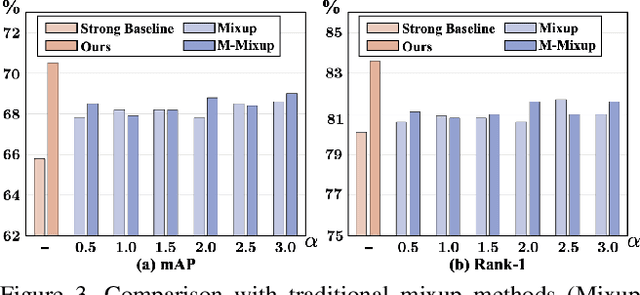
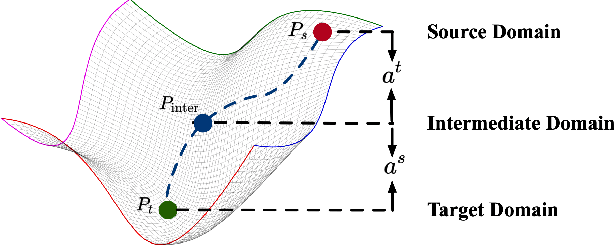
Unsupervised domain adaptive person re-identification (UDA re-ID) aims at transferring the labeled source domain's knowledge to improve the model's discriminability on the unlabeled target domain. From a novel perspective, we argue that the bridging between the source and target domains can be utilized to tackle the UDA re-ID task, and we focus on explicitly modeling appropriate intermediate domains to characterize this bridging. Specifically, we propose an Intermediate Domain Module (IDM) to generate intermediate domains' representations on-the-fly by mixing the source and target domains' hidden representations using two domain factors. Based on the "shortest geodesic path" definition, i.e., the intermediate domains along the shortest geodesic path between the two extreme domains can play a better bridging role, we propose two properties that these intermediate domains should satisfy. To ensure these two properties to better characterize appropriate intermediate domains, we enforce the bridge losses on intermediate domains' prediction space and feature space, and enforce a diversity loss on the two domain factors. The bridge losses aim at guiding the distribution of appropriate intermediate domains to keep the right distance to the source and target domains. The diversity loss serves as a regularization to prevent the generated intermediate domains from being over-fitting to either of the source and target domains. Our proposed method outperforms the state-of-the-arts by a large margin in all the common UDA re-ID tasks, and the mAP gain is up to 7.7% on the challenging MSMT17 benchmark. Code is available at https://github.com/SikaStar/IDM.
Generalizable Person Re-identification with Relevance-aware Mixture of Experts
May 19, 2021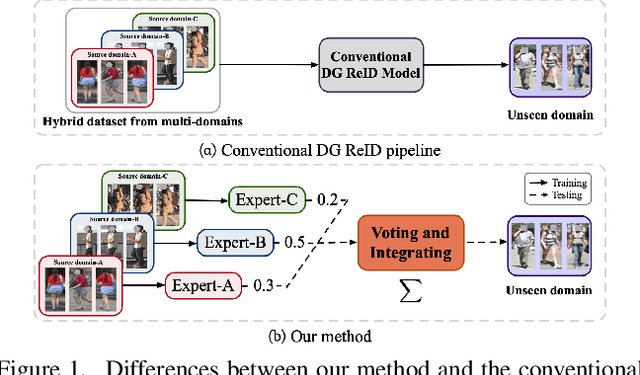
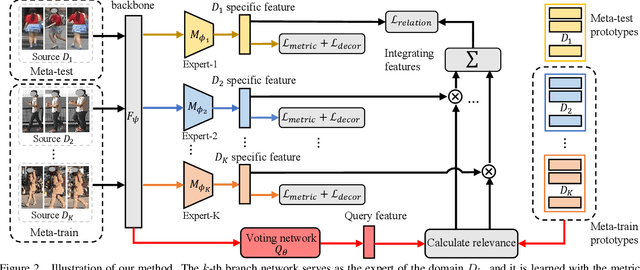
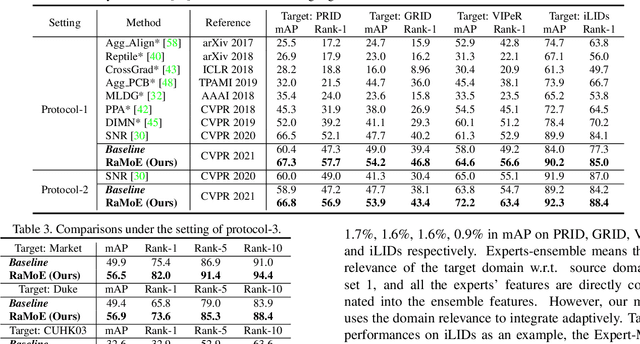
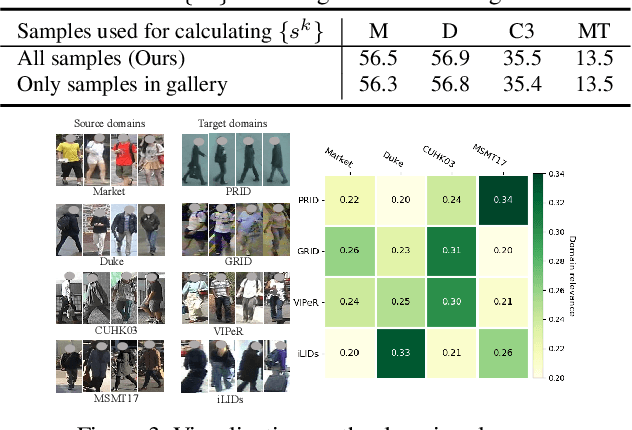
Domain generalizable (DG) person re-identification (ReID) is a challenging problem because we cannot access any unseen target domain data during training. Almost all the existing DG ReID methods follow the same pipeline where they use a hybrid dataset from multiple source domains for training, and then directly apply the trained model to the unseen target domains for testing. These methods often neglect individual source domains' discriminative characteristics and their relevances w.r.t. the unseen target domains, though both of which can be leveraged to help the model's generalization. To handle the above two issues, we propose a novel method called the relevance-aware mixture of experts (RaMoE), using an effective voting-based mixture mechanism to dynamically leverage source domains' diverse characteristics to improve the model's generalization. Specifically, we propose a decorrelation loss to make the source domain networks (experts) keep the diversity and discriminability of individual domains' characteristics. Besides, we design a voting network to adaptively integrate all the experts' features into the more generalizable aggregated features with domain relevance. Considering the target domains' invisibility during training, we propose a novel learning-to-learn algorithm combined with our relation alignment loss to update the voting network. Extensive experiments demonstrate that our proposed RaMoE outperforms the state-of-the-art methods.
Dual-Refinement: Joint Label and Feature Refinement for Unsupervised Domain Adaptive Person Re-Identification
Jan 17, 2021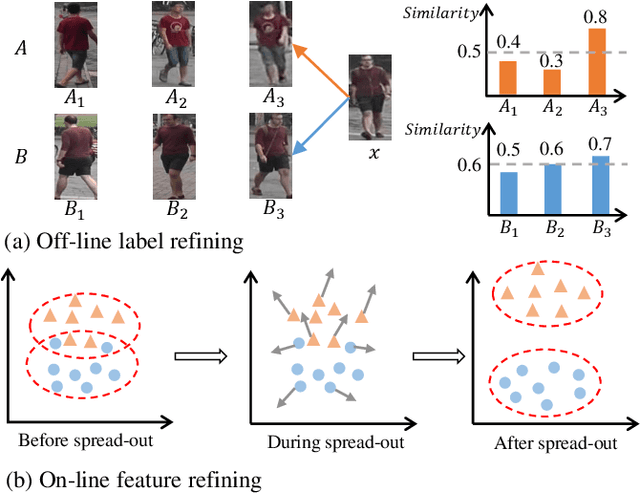
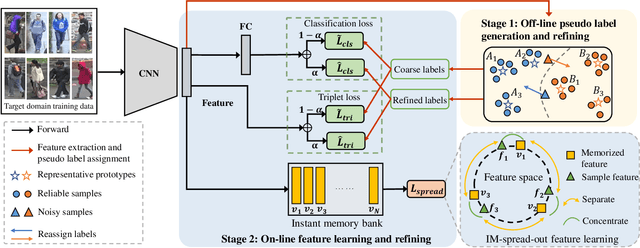
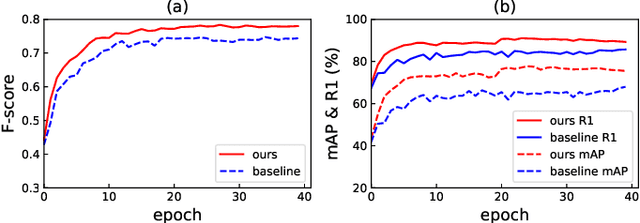
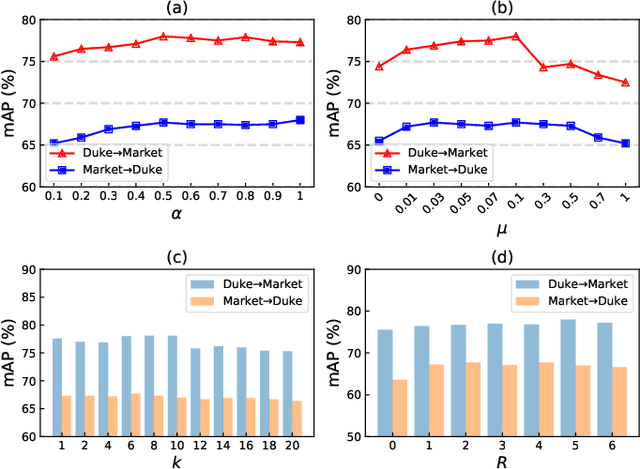
Unsupervised domain adaptive (UDA) person re-identification (re-ID) is a challenging task due to the missing of labels for the target domain data. To handle this problem, some recent works adopt clustering algorithms to off-line generate pseudo labels, which can then be used as the supervision signal for on-line feature learning in the target domain. However, the off-line generated labels often contain lots of noise that significantly hinders the discriminability of the on-line learned features, and thus limits the final UDA re-ID performance. To this end, we propose a novel approach, called Dual-Refinement, that jointly refines pseudo labels at the off-line clustering phase and features at the on-line training phase, to alternatively boost the label purity and feature discriminability in the target domain for more reliable re-ID. Specifically, at the off-line phase, a new hierarchical clustering scheme is proposed, which selects representative prototypes for every coarse cluster. Thus, labels can be effectively refined by using the inherent hierarchical information of person images. Besides, at the on-line phase, we propose an instant memory spread-out (IM-spread-out) regularization, that takes advantage of the proposed instant memory bank to store sample features of the entire dataset and enable spread-out feature learning over the entire training data instantly. Our Dual-Refinement method reduces the influence of noisy labels and refines the learned features within the alternative training process. Experiments demonstrate that our method outperforms the state-of-the-art methods by a large margin.