 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgemc-BEiT: Multi-choice Discretization for Image BERT Pre-training
Paper and Code
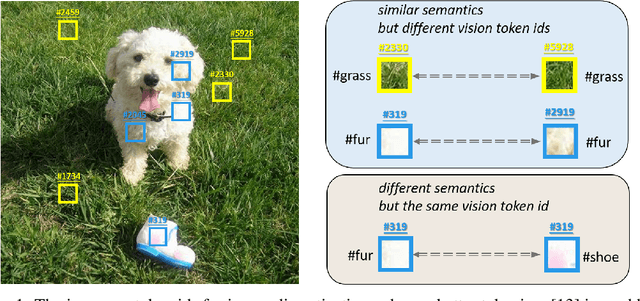


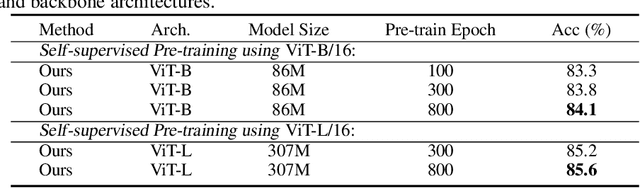
Image BERT pre-training with masked image modeling (MIM) becomes a popular practice to cope with self-supervised representation learning. A seminal work, BEiT, casts MIM as a classification task with a visual vocabulary, tokenizing the continuous visual signals into discrete vision tokens using a pre-learned dVAE. Despite a feasible solution, the improper discretization hinders further improvements of image pre-training. Since image discretization has no ground-truth answers, we believe that the masked patch should not be assigned with a unique token id even if a better tokenizer can be obtained. In this work, we introduce an improved BERT-style image pre-training method, namely mc-BEiT, which performs MIM proxy tasks towards eased and refined multi-choice training objectives. Specifically, the multi-choice supervision for the masked image patches is formed by the soft probability vectors of the discrete token ids, which are predicted by the off-the-shelf image tokenizer and further refined by high-level inter-patch perceptions resorting to the observation that similar patches should share their choices. Extensive experiments on classification, segmentation, and detection tasks demonstrate the superiority of our method, e.g., the pre-trained ViT-B achieves 84.1% top-1 fine-tuning accuracy on ImageNet-1K classification, 50.8% mIOU on ADE20K semantic segmentation, 51.2% AP^b and 44.3% AP^m of object detection and instance segmentation on COCO, outperforming the competitive counterparts.