 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChiMDQA: Towards Comprehensive Chinese Document QA with Fine-grained Evaluation
Nov 05, 2025With the rapid advancement of natural language processing (NLP) technologies, the demand for high-quality Chinese document question-answering datasets is steadily growing. To address this issue, we present the Chinese Multi-Document Question Answering Dataset(ChiMDQA), specifically designed for downstream business scenarios across prevalent domains including academic, education, finance, law, medical treatment, and news. ChiMDQA encompasses long-form documents from six distinct fields, consisting of 6,068 rigorously curated, high-quality question-answer (QA) pairs further classified into ten fine-grained categories. Through meticulous document screening and a systematic question-design methodology, the dataset guarantees both diversity and high quality, rendering it applicable to various NLP tasks such as document comprehension, knowledge extraction, and intelligent QA systems. Additionally, this paper offers a comprehensive overview of the dataset's design objectives, construction methodologies, and fine-grained evaluation system, supplying a substantial foundation for future research and practical applications in Chinese QA. The code and data are available at: https://anonymous.4open.science/r/Foxit-CHiMDQA/.
Deep Video Coding with Dual-Path Generative Adversarial Network
Nov 29, 2021

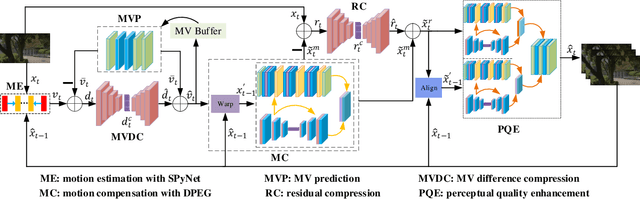
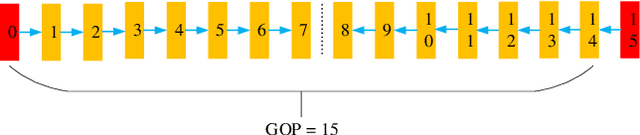
The deep-learning-based video coding has attracted substantial attention for its great potential to squeeze out the spatial-temporal redundancies of video sequences. This paper proposes an efficient codec namely dual-path generative adversarial network-based video codec (DGVC). First, we propose a dual-path enhancement with generative adversarial network (DPEG) to reconstruct the compressed video details. The DPEG consists of an $\alpha$-path of auto-encoder and convolutional long short-term memory (ConvLSTM), which facilitates the structure feature reconstruction with a large receptive field and multi-frame references, and a $\beta$-path of residual attention blocks, which facilitates the reconstruction of local texture features. Both paths are fused and co-trained by a generative-adversarial process. Second, we reuse the DPEG network in both motion compensation and quality enhancement modules, which are further combined with motion estimation and entropy coding modules in our DGVC framework. Third, we employ a joint training of deep video compression and enhancement to further improve the rate-distortion (RD) performance. Compared with x265 LDP very fast mode, our DGVC reduces the average bit-per-pixel (bpp) by 39.39%/54.92% at the same PSNR/MS-SSIM, which outperforms the state-of-the art deep video codecs by a considerable margin.