 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Globally Consistent Stochastic Human Motion Prediction via Motion Diffusion
Paper and Code
May 21, 2023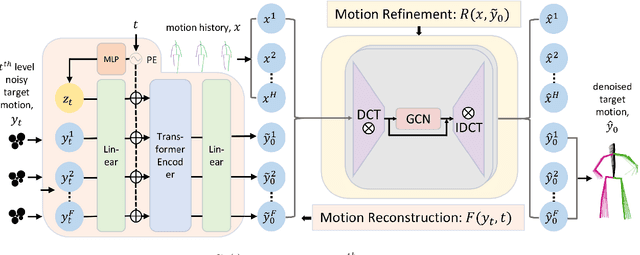
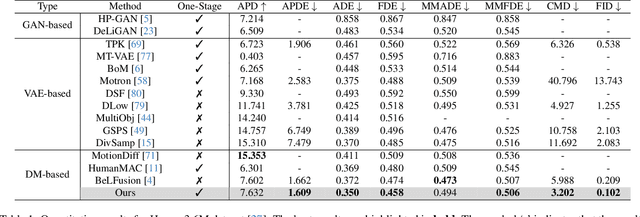
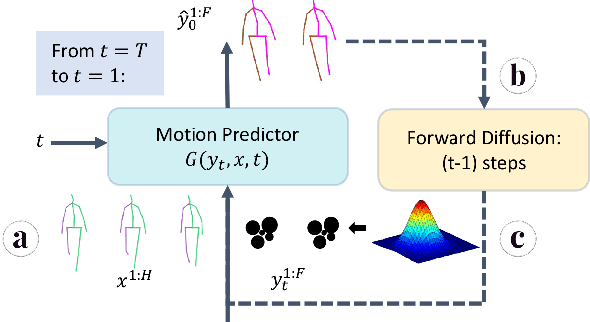

Stochastic human motion prediction aims to predict multiple possible upcoming pose sequences based on past human motion trajectories. Prior works focused heavily on generating diverse motion samples, leading to inconsistent, abnormal predictions from the immediate past observations. To address this issue, in this work, we propose DiffMotion, a diffusion-based stochastic human motion prediction framework that considers both the kinematic structure of the human body and the globally temporally consistent nature of motion. Specifically, DiffMotion consists of two modules: 1) a transformer-based network for generating an initial motion reconstruction from corrupted motion, and 2) a multi-stage graph convolutional network to iteratively refine the generated motion based on past observations. Facilitated by the proposed direct target prediction objective and the variance scheduler, our method is capable of predicting accurate, realistic and consistent motion with an appropriate level of diversity. Our results on benchmark datasets demonstrate that DiffMotion outperforms previous methods by large margins in terms of accuracy and fidelity while demonstrating superior robustness.