 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Augmentation for Continual RL via Adversarial Gradient Episodic Memory
Paper and Code
Aug 27, 2024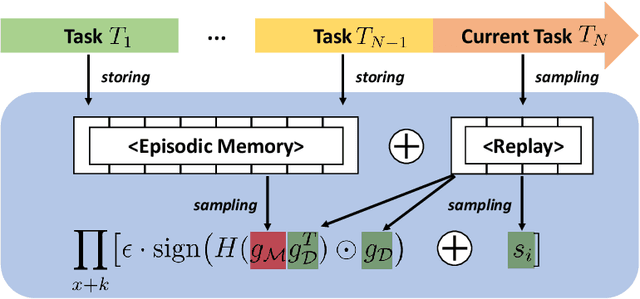
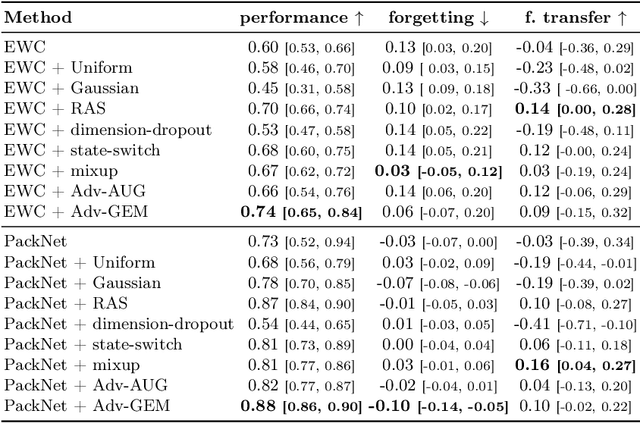
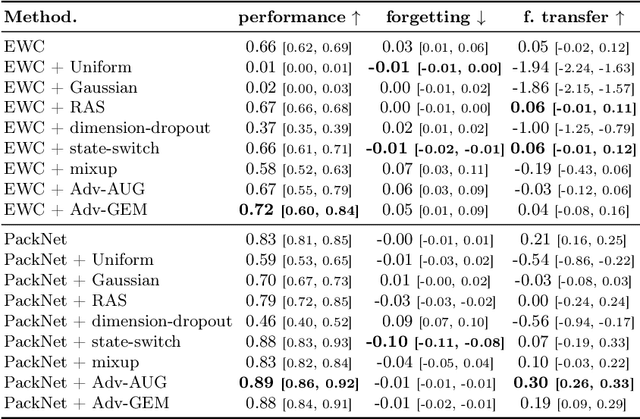
Data efficiency of learning, which plays a key role in the Reinforcement Learning (RL) training process, becomes even more important in continual RL with sequential environments. In continual RL, the learner interacts with non-stationary, sequential tasks and is required to learn new tasks without forgetting previous knowledge. However, there is little work on implementing data augmentation for continual RL. In this paper, we investigate the efficacy of data augmentation for continual RL. Specifically, we provide benchmarking data augmentations for continual RL, by (1) summarising existing data augmentation methods and (2) including a new augmentation method for continual RL: Adversarial Augmentation with Gradient Episodic Memory (Adv-GEM). Extensive experiments show that data augmentations, such as random amplitude scaling, state-switch, mixup, adversarial augmentation, and Adv-GEM, can improve existing continual RL algorithms in terms of their average performance, catastrophic forgetting, and forward transfer, on robot control tasks. All data augmentation methods are implemented as plug-in modules for trivial integration into continual RL methods.