 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Adversarial Video Attacks with Spatial Transformations
Paper and Code


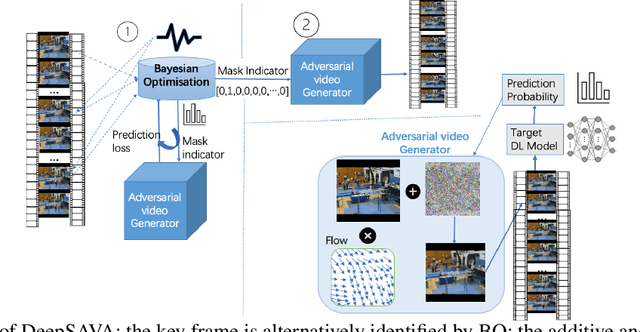

In recent years, a significant amount of research efforts concentrated on adversarial attacks on images, while adversarial video attacks have seldom been explored. We propose an adversarial attack strategy on videos, called DeepSAVA. Our model includes both additive perturbation and spatial transformation by a unified optimisation framework, where the structural similarity index (SSIM) measure is adopted to measure the adversarial distance. We design an effective and novel optimisation scheme which alternatively utilizes Bayesian optimisation to identify the most influential frame in a video and Stochastic gradient descent (SGD) based optimisation to produce both additive and spatial-transformed perturbations. Doing so enables DeepSAVA to perform a very sparse attack on videos for maintaining human imperceptibility while still achieving state-of-the-art performance in terms of both attack success rate and adversarial transferability. Our intensive experiments on various types of deep neural networks and video datasets confirm the superiority of DeepSAVA.