 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreating and Reenacting Controllable 3D Humans with Differentiable Rendering
Oct 22, 2021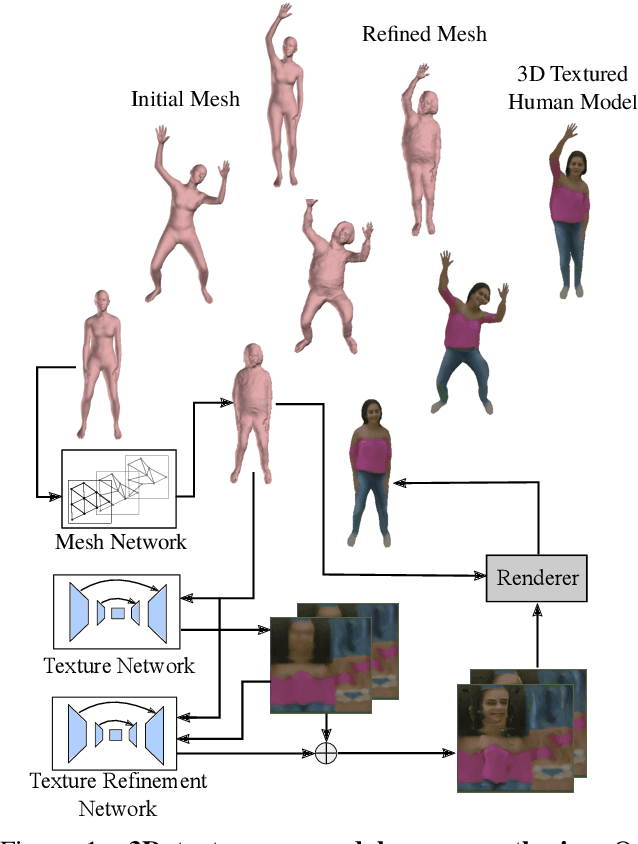
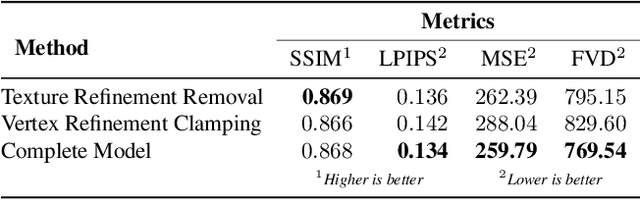
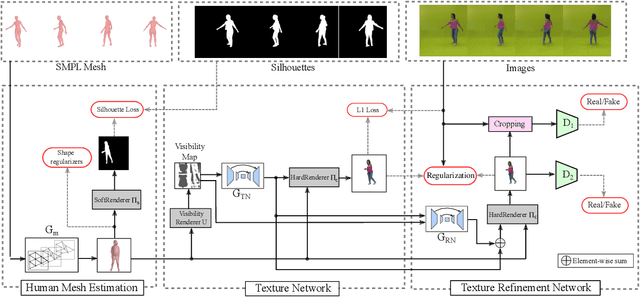

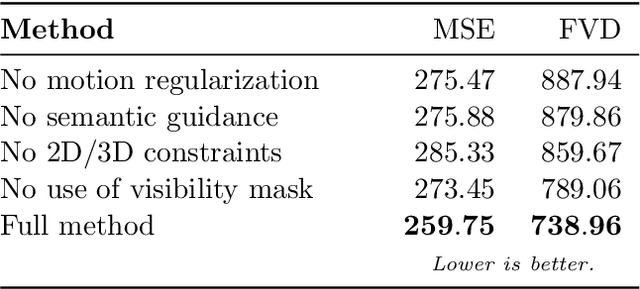
This paper proposes a new end-to-end neural rendering architecture to transfer appearance and reenact human actors. Our method leverages a carefully designed graph convolutional network (GCN) to model the human body manifold structure, jointly with differentiable rendering, to synthesize new videos of people in different contexts from where they were initially recorded. Unlike recent appearance transferring methods, our approach can reconstruct a fully controllable 3D texture-mapped model of a person, while taking into account the manifold structure from body shape and texture appearance in the view synthesis. Specifically, our approach models mesh deformations with a three-stage GCN trained in a self-supervised manner on rendered silhouettes of the human body. It also infers texture appearance with a convolutional network in the texture domain, which is trained in an adversarial regime to reconstruct human texture from rendered images of actors in different poses. Experiments on different videos show that our method successfully infers specific body deformations and avoid creating texture artifacts while achieving the best values for appearance in terms of Structural Similarity (SSIM), Learned Perceptual Image Patch Similarity (LPIPS), Mean Squared Error (MSE), and Fr\'echet Video Distance (FVD). By taking advantages of both differentiable rendering and the 3D parametric model, our method is fully controllable, which allows controlling the human synthesis from both pose and rendering parameters. The source code is available at https://www.verlab.dcc.ufmg.br/retargeting-motion/wacv2022.
On Development and Evaluation of Retargeting Human Motion and Appearance in Monocular Videos
Mar 29, 2021
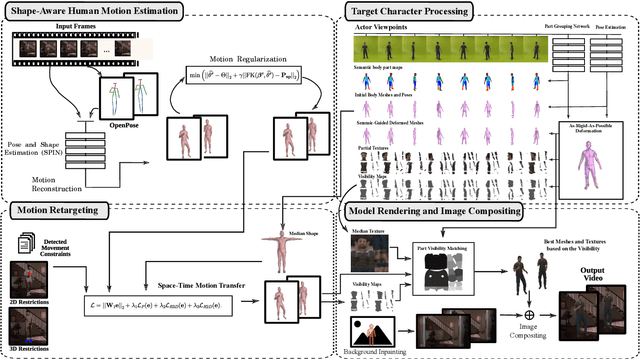
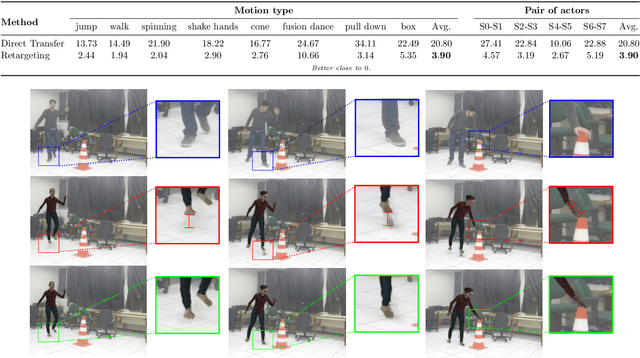
Transferring human motion and appearance between videos of human actors remains one of the key challenges in Computer Vision. Despite the advances from recent image-to-image translation approaches, there are several transferring contexts where most end-to-end learning-based retargeting methods still perform poorly. Transferring human appearance from one actor to another is only ensured when a strict setup has been complied, which is generally built considering their training regime's specificities. The contribution of this paper is two-fold: first, we propose a novel and high-performant approach based on a hybrid image-based rendering technique that exhibits competitive visual retargeting quality compared to state-of-the-art neural rendering approaches. The formulation leverages user body shape into the retargeting while considering physical constraints of the motion in 3D and the 2D image domain. We also present a new video retargeting benchmark dataset composed of different videos with annotated human motions to evaluate the task of synthesizing people's videos, which can be used as a common base to improve tracking the progress in the field. The dataset and its evaluation protocols are designed to evaluate retargeting methods in more general and challenging conditions. Our method is validated in several experiments, comprising publicly available videos of actors with different shapes, motion types and camera setups. The dataset and retargeting code are publicly available to the community at: https://www.verlab.dcc.ufmg.br/retargeting-motion.
Learning to dance: A graph convolutional adversarial network to generate realistic dance motions from audio
Nov 30, 2020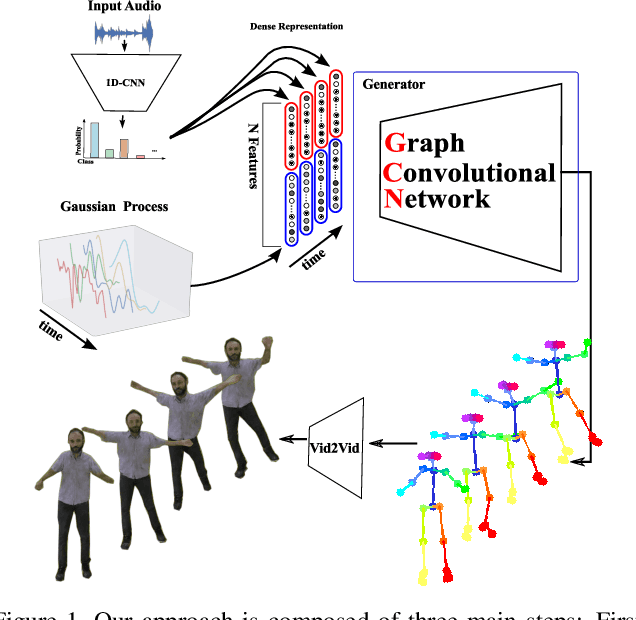
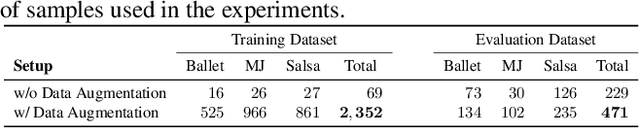
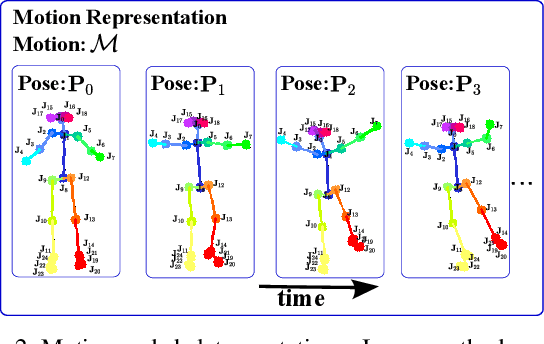
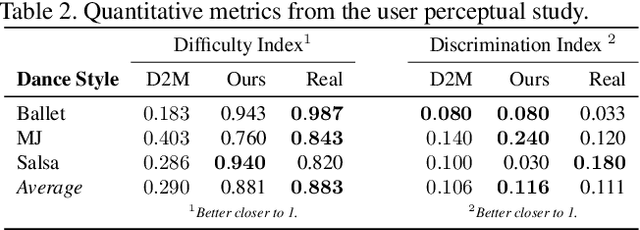
Synthesizing human motion through learning techniques is becoming an increasingly popular approach to alleviating the requirement of new data capture to produce animations. Learning to move naturally from music, i.e., to dance, is one of the more complex motions humans often perform effortlessly. Each dance movement is unique, yet such movements maintain the core characteristics of the dance style. Most approaches addressing this problem with classical convolutional and recursive neural models undergo training and variability issues due to the non-Euclidean geometry of the motion manifold structure.In this paper, we design a novel method based on graph convolutional networks to tackle the problem of automatic dance generation from audio information. Our method uses an adversarial learning scheme conditioned on the input music audios to create natural motions preserving the key movements of different music styles. We evaluate our method with three quantitative metrics of generative methods and a user study. The results suggest that the proposed GCN model outperforms the state-of-the-art dance generation method conditioned on music in different experiments. Moreover, our graph-convolutional approach is simpler, easier to be trained, and capable of generating more realistic motion styles regarding qualitative and different quantitative metrics. It also presented a visual movement perceptual quality comparable to real motion data.
Do As I Do: Transferring Human Motion and Appearance between Monocular Videos with Spatial and Temporal Constraints
Jan 21, 2020


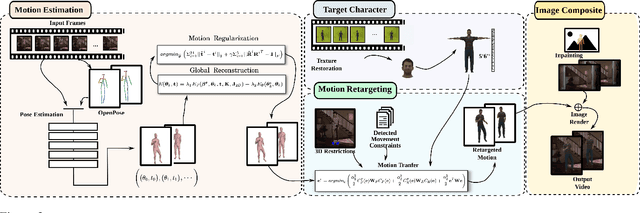
Creating plausible virtual actors from images of real actors remains one of the key challenges in computer vision and computer graphics. Marker-less human motion estimation and shape modeling from images in the wild bring this challenge to the fore. Although the recent advances on view synthesis and image-to-image translation, currently available formulations are limited to transfer solely style and do not take into account the character's motion and shape, which are by nature intermingled to produce plausible human forms. In this paper, we propose a unifying formulation for transferring appearance and retargeting human motion from monocular videos that regards all these aspects. Our method synthesizes new videos of people in a different context where they were initially recorded. Differently from recent appearance transferring methods, our approach takes into account body shape, appearance, and motion constraints. The evaluation is performed with several experiments using publicly available real videos containing hard conditions. Our method is able to transfer both human motion and appearance outperforming state-of-the-art methods, while preserving specific features of the motion that must be maintained (e.g., feet touching the floor, hands touching a particular object) and holding the best visual quality and appearance metrics such as Structural Similarity (SSIM) and Learned Perceptual Image Patch Similarity (LPIPS).