 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperJump: Accelerating HyperBand via Risk Modelling
Paper and Code

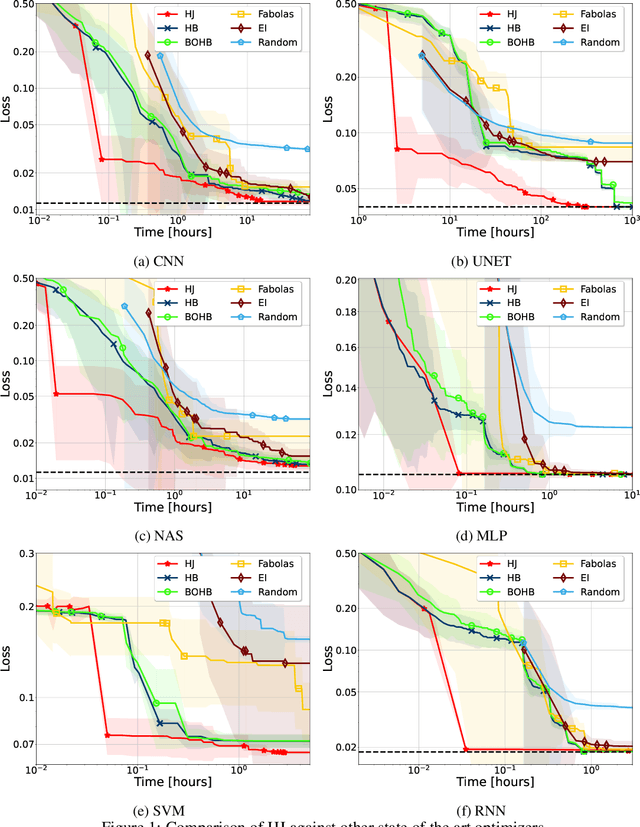

In the literature on hyper-parameter tuning, a number of recent solutions rely on low-fidelity observations (e.g., training with sub-sampled datasets or for short periods of time) to extrapolate good configurations to use when performing full training. Among these, HyperBand is arguably one of the most popular solutions, due to its efficiency and theoretically provable robustness. In this work, we introduce HyperJump, a new approach that builds on HyperBand's robust search strategy and complements it with novel model-based risk analysis techniques that accelerate the search by jumping the evaluation of low risk configurations, i.e., configurations that are likely to be discarded by HyperBand. We evaluate HyperJump on a suite of hyper-parameter optimization problems and show that it provides over one-order of magnitude speed-ups on a variety of deep-learning and kernel-based learning problems when compared to HyperBand as well as to a number of state of the art optimizers.