 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRadVLM: A Multitask Conversational Vision-Language Model for Radiology
Feb 05, 2025



The widespread use of chest X-rays (CXRs), coupled with a shortage of radiologists, has driven growing interest in automated CXR analysis and AI-assisted reporting. While existing vision-language models (VLMs) show promise in specific tasks such as report generation or abnormality detection, they often lack support for interactive diagnostic capabilities. In this work we present RadVLM, a compact, multitask conversational foundation model designed for CXR interpretation. To this end, we curate a large-scale instruction dataset comprising over 1 million image-instruction pairs containing both single-turn tasks -- such as report generation, abnormality classification, and visual grounding -- and multi-turn, multi-task conversational interactions. After fine-tuning RadVLM on this instruction dataset, we evaluate it across different tasks along with re-implemented baseline VLMs. Our results show that RadVLM achieves state-of-the-art performance in conversational capabilities and visual grounding while remaining competitive in other radiology tasks. Ablation studies further highlight the benefit of joint training across multiple tasks, particularly for scenarios with limited annotated data. Together, these findings highlight the potential of RadVLM as a clinically relevant AI assistant, providing structured CXR interpretation and conversational capabilities to support more effective and accessible diagnostic workflows.
Reconstruction of Patient-Specific Confounders in AI-based Radiologic Image Interpretation using Generative Pretraining
Sep 29, 2023

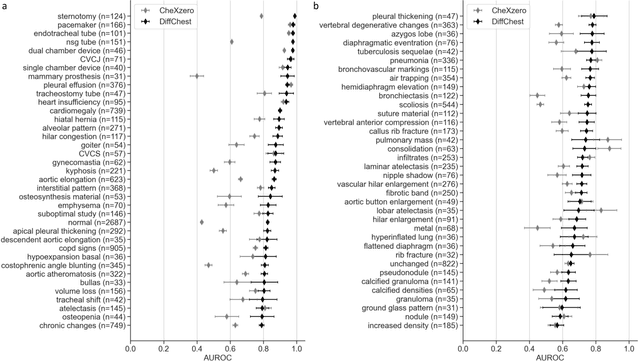

Detecting misleading patterns in automated diagnostic assistance systems, such as those powered by Artificial Intelligence, is critical to ensuring their reliability, particularly in healthcare. Current techniques for evaluating deep learning models cannot visualize confounding factors at a diagnostic level. Here, we propose a self-conditioned diffusion model termed DiffChest and train it on a dataset of 515,704 chest radiographs from 194,956 patients from multiple healthcare centers in the United States and Europe. DiffChest explains classifications on a patient-specific level and visualizes the confounding factors that may mislead the model. We found high inter-reader agreement when evaluating DiffChest's capability to identify treatment-related confounders, with Fleiss' Kappa values of 0.8 or higher across most imaging findings. Confounders were accurately captured with 11.1% to 100% prevalence rates. Furthermore, our pretraining process optimized the model to capture the most relevant information from the input radiographs. DiffChest achieved excellent diagnostic accuracy when diagnosing 11 chest conditions, such as pleural effusion and cardiac insufficiency, and at least sufficient diagnostic accuracy for the remaining conditions. Our findings highlight the potential of pretraining based on diffusion models in medical image classification, specifically in providing insights into confounding factors and model robustness.