Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Processing of Out-Of-Vocabulary Words in a Spoken Dialogue System
Paper and Code
Sep 17, 1997

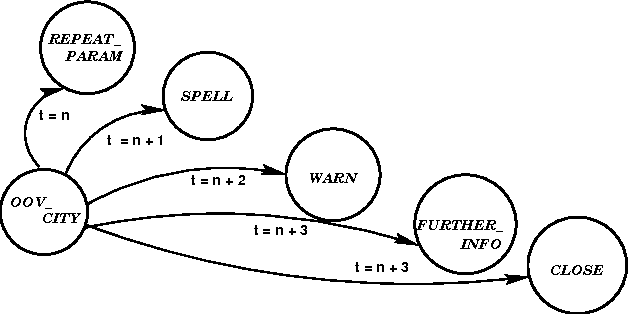
One of the most important causes of failure in spoken dialogue systems is usually neglected: the problem of words that are not covered by the system's vocabulary (out-of-vocabulary or OOV words). In this paper a methodology is described for the detection, classification and processing of OOV words in an automatic train timetable information system. The various extensions that had to be effected on the different modules of the system are reported, resulting in the design of appropriate dialogue strategies, as are encouraging evaluation results on the new versions of the word recogniser and the linguistic processor.
* Proceedings of EUROSPEECH'97, Vol.4, pp.1887-1890, Rhodes, Greece * 4 pages, 2 eps figures, requires LaTeX2e, uses eurospeech.sty and
epsfig
View paper on