 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Learning Strategies to Model Pathological Speech: Effect of Multiple Spectral Resolutions
Sep 17, 2022


This paper considers a representation learning strategy to model speech signals from patients with Parkinson's disease and cleft lip and palate. In particular, it compares different parametrized representation types such as wideband and narrowband spectrograms, and wavelet-based scalograms, with the goal of quantifying the representation capacity of each. Methods for quantification include the ability of the proposed model to classify different pathologies and the associated disease severity. Additionally, this paper proposes a novel fusion strategy called multi-spectral fusion that combines wideband and narrowband spectral resolutions using a representation learning strategy based on autoencoders. The proposed models are able to classify the speech from Parkinson's disease patients with accuracy up to 95\%. The proposed models were also able to asses the dysarthria severity of Parkinson's disease patients with a Spearman correlation up to 0.75. These results outperform those observed in literature where the same problem was addressed with the same corpus.
Self-Supervised Speech Representations Preserve Speech Characteristics while Anonymizing Voices
Apr 04, 2022
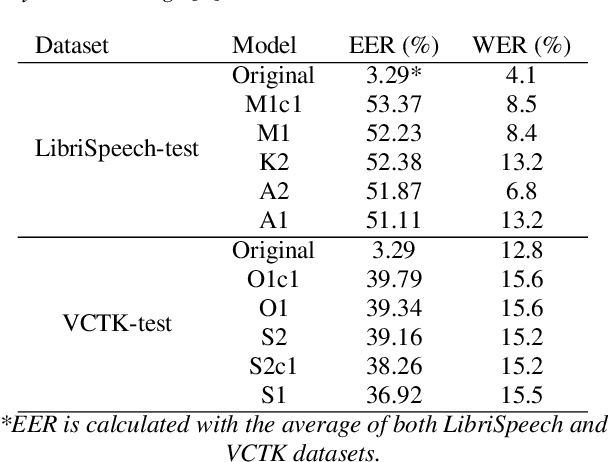

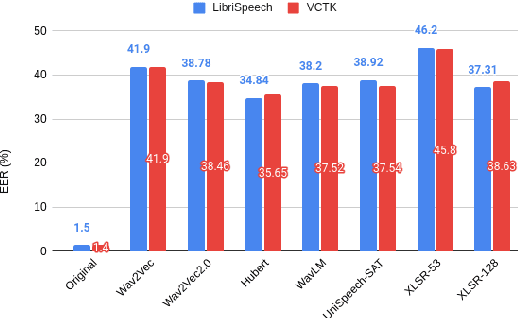
Collecting speech data is an important step in training speech recognition systems and other speech-based machine learning models. However, the issue of privacy protection is an increasing concern that must be addressed. The current study investigates the use of voice conversion as a method for anonymizing voices. In particular, we train several voice conversion models using self-supervised speech representations including Wav2Vec2.0, Hubert and UniSpeech. Converted voices retain a low word error rate within 1% of the original voice. Equal error rate increases from 1.52% to 46.24% on the LibriSpeech test set and from 3.75% to 45.84% on speakers from the VCTK corpus which signifies degraded performance on speaker verification. Lastly, we conduct experiments on dysarthric speech data to show that speech features relevant to articulation, prosody, phonation and phonology can be extracted from anonymized voices for discriminating between healthy and pathological speech.
The Phonetic Footprint of Parkinson's Disease
Dec 21, 2021
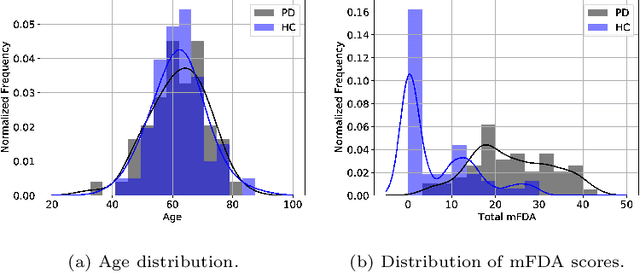
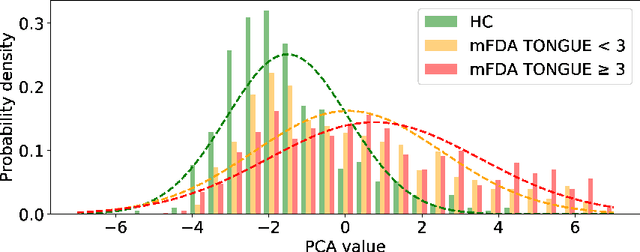
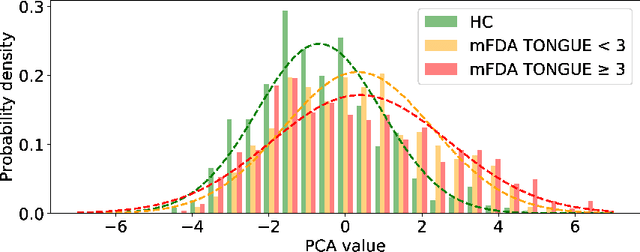
As one of the most prevalent neurodegenerative disorders, Parkinson's disease (PD) has a significant impact on the fine motor skills of patients. The complex interplay of different articulators during speech production and realization of required muscle tension become increasingly difficult, thus leading to a dysarthric speech. Characteristic patterns such as vowel instability, slurred pronunciation and slow speech can often be observed in the affected individuals and were analyzed in previous studies to determine the presence and progression of PD. In this work, we used a phonetic recognizer trained exclusively on healthy speech data to investigate how PD affected the phonetic footprint of patients. We rediscovered numerous patterns that had been described in previous contributions although our system had never seen any pathological speech previously. Furthermore, we could show that intermediate activations from the neural network could serve as feature vectors encoding information related to the disease state of individuals. We were also able to directly correlate the expert-rated intelligibility of a speaker with the mean confidence of phonetic predictions. Our results support the assumption that pathological data is not necessarily required to train systems that are capable of analyzing PD speech.
* https://www.sciencedirect.com/science/article/abs/pii/S0885230821001169