 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Phonological Feature Recognition with Self-Supervised Speech Models
May 25, 2026Phonological features provide a language-general and linguistically grounded representation of speech. We present PhonoQ-2.0, a multilingual frame-level phonological feature recognizer built on self-supervised speech models. The system directly predicts a structured 22-dimensional feature vector per frame encoding manner, vowel quality, place, and voicing, instead of deriving features from phoneme outputs. To ensure phonologically coherent predictions, we introduce a manner-conditioned gating mechanism that activates valid feature groups. Evaluated across multiple languages and corpora, PhonoQ-2.0 achieves an average macro-F1 of 91.3% in-domain and 88.9% out-of-domain. Compared to a strong CTC phoneme baseline, it delivers consistent gains of +8.8 F1 in-domain and +8.6 out-of-domain on average. In unseen-language evaluation, PhonoQ-2.0 improves macro-F1 from 66.9% to 73.6% (+6.7 on average), with gains of up to +10.8 points.
Adapting Self-Supervised Speech Representations for Cross-lingual Dysarthria Detection in Parkinson's Disease
Mar 23, 2026The limited availability of dysarthric speech data makes cross-lingual detection an important but challenging problem. A key difficulty is that speech representations often encode language-dependent structure that can confound dysarthria detection. We propose a representation-level language shift (LS) that aligns source-language self-supervised speech representations with the target-language distribution using centroid-based vector adaptation estimated from healthy-control speech. We evaluate the approach on oral DDK recordings from Parkinson's disease speech datasets in Czech, German, and Spanish under both cross-lingual and multilingual settings. LS substantially improves sensitivity and F1 in cross-lingual settings, while yielding smaller but consistent gains in multilingual settings. Representation analysis further shows that LS reduces language identity in the embedding space, supporting the interpretation that LS removes language-dependent structure.
Self-Supervised Speech Representations Preserve Speech Characteristics while Anonymizing Voices
Apr 04, 2022
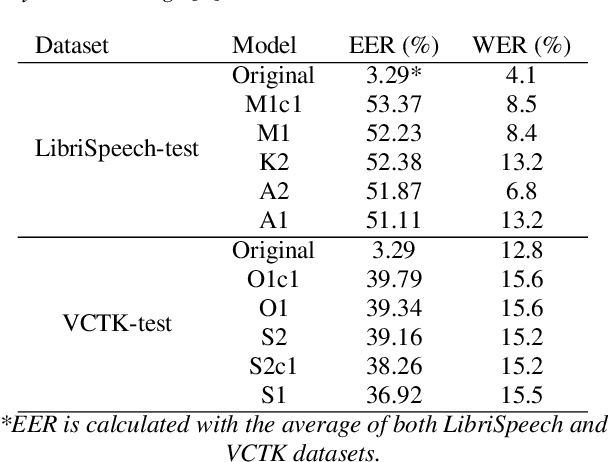

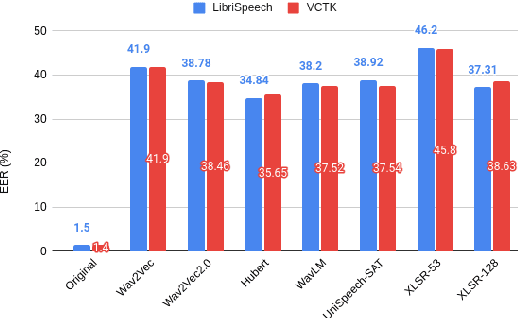
Collecting speech data is an important step in training speech recognition systems and other speech-based machine learning models. However, the issue of privacy protection is an increasing concern that must be addressed. The current study investigates the use of voice conversion as a method for anonymizing voices. In particular, we train several voice conversion models using self-supervised speech representations including Wav2Vec2.0, Hubert and UniSpeech. Converted voices retain a low word error rate within 1% of the original voice. Equal error rate increases from 1.52% to 46.24% on the LibriSpeech test set and from 3.75% to 45.84% on speakers from the VCTK corpus which signifies degraded performance on speaker verification. Lastly, we conduct experiments on dysarthric speech data to show that speech features relevant to articulation, prosody, phonation and phonology can be extracted from anonymized voices for discriminating between healthy and pathological speech.
Cross-lingual Self-Supervised Speech Representations for Improved Dysarthric Speech Recognition
Apr 04, 2022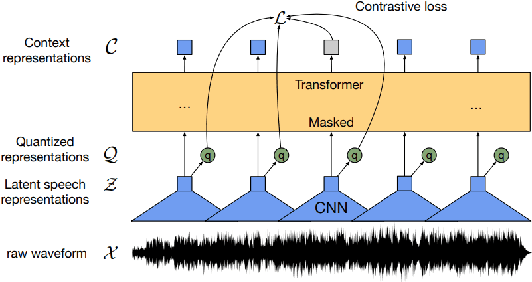

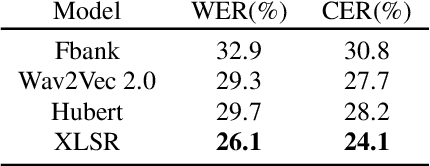
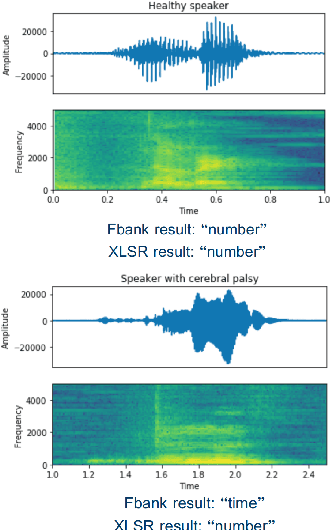
State-of-the-art automatic speech recognition (ASR) systems perform well on healthy speech. However, the performance on impaired speech still remains an issue. The current study explores the usefulness of using Wav2Vec self-supervised speech representations as features for training an ASR system for dysarthric speech. Dysarthric speech recognition is particularly difficult as several aspects of speech such as articulation, prosody and phonation can be impaired. Specifically, we train an acoustic model with features extracted from Wav2Vec, Hubert, and the cross-lingual XLSR model. Results suggest that speech representations pretrained on large unlabelled data can improve word error rate (WER) performance. In particular, features from the multilingual model led to lower WERs than filterbanks (Fbank) or models trained on a single language. Improvements were observed in English speakers with cerebral palsy caused dysarthria (UASpeech corpus), Spanish speakers with Parkinsonian dysarthria (PC-GITA corpus) and Italian speakers with paralysis-based dysarthria (EasyCall corpus). Compared to using Fbank features, XLSR-based features reduced WERs by 6.8%, 22.0%, and 7.0% for the UASpeech, PC-GITA, and EasyCall corpus, respectively.
SliTraNet: Automatic Detection of Slide Transitions in Lecture Videos using Convolutional Neural Networks
Feb 07, 2022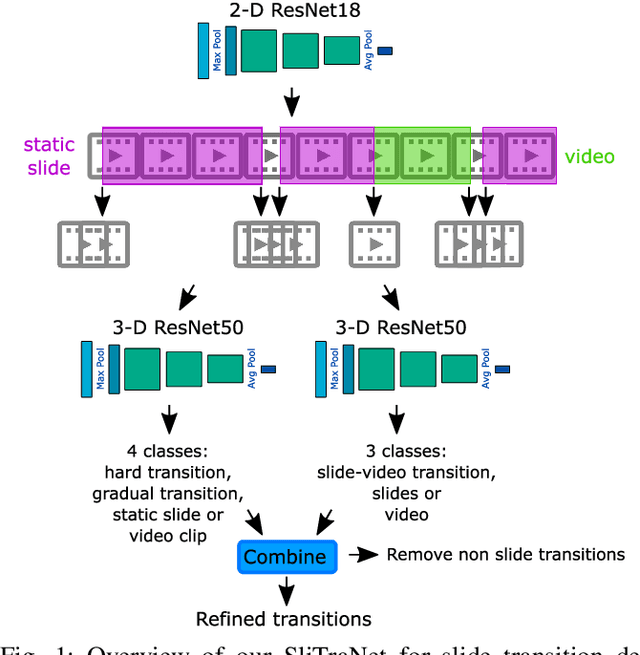
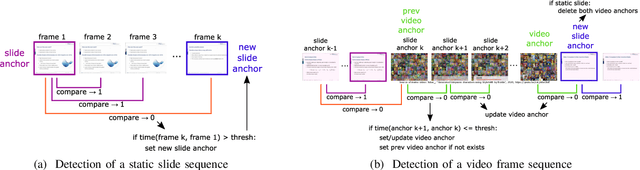
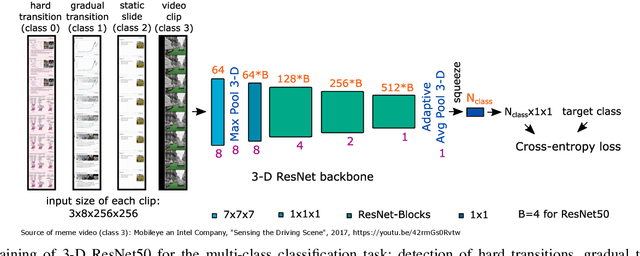

With the increasing number of online learning material in the web, search for specific content in lecture videos can be time consuming. Therefore, automatic slide extraction from the lecture videos can be helpful to give a brief overview of the main content and to support the students in their studies. For this task, we propose a deep learning method to detect slide transitions in lectures videos. We first process each frame of the video by a heuristic-based approach using a 2-D convolutional neural network to predict transition candidates. Then, we increase the complexity by employing two 3-D convolutional neural networks to refine the transition candidates. Evaluation results demonstrate the effectiveness of our method in finding slide transitions.